Legend of the Stalwart Mouse: Return of the MX518
Published 5 years, 1 month pastI’ve relied on a mouse for about a decade and a half. I don’t mean “relied on a mouse” in the generic sense, but rather in the sense that I’ve relied on one very specific and venerable mouse: a Logitech MX500.
I’ve had it for so long, I’d forgotten how long I’ve had it. I searched for information about its production dates and wouldn’t you know it, Wikipedia has an article devoted solely to Logitech products throughout history, because of course it does, and it lists (among other things) their dates of release. The MX500 was released in 2002, and superseded by the MX510 in 2004. I then remembered a photo I took of my eldest child when she was an infant, trying to chew on a computer mouse. I dug it out of my iPhoto library and yep, it’s my MX500. The picture is dated June 2004.
So I have photographic evidence that I’ve used this specific mouse for 15 years or more. The logo plate on top of the mouse has been worn half-smooth and half-paintless by the palm of my hand, much like the shiny-smooth areas worn into the subtle matte surface texture where the thumb and pinky finger grip the sides. The model and technical information printed on the underside has similarly worn away. It started out with four little oval glide nubs on the underside that held the bottom away from the desk surface; only one remains. Even though, as an optical mouse, it can be used on any surface, I eventually went back to soft mousepads, so as to limit further undercarriage damage.

Why have I been so devoted to this mouse? Well, it’s incredibly well engineered, for one — it’s put up with 15 years of daily use. It’s exactly the right shape for my hand, and it has multiple configurable inputs right where I expect them. There are arrow buttons just above my thumb which I use as forward/backward in browsers, buttons above and below the scroll wheel that I map to Page Up/Page Down, an extra button at almost the apex of the mouse’s back mapped to ⌥⇥ (Option-Tab), and the usual right/left mouse click buttons. Plus the scroll wheel is itself a push-down-to-click button.
Most of these features can be found on one mouse or another, but it’s rare to find them all in one mouse — and next to impossible to find them in a shape and size that feels comfortable to me. I’d occasionally looked at the secondary market, but even used, the MX500 can command three figures. I checked Amazon as I wrote this, and an unused MX500 was listing for two hundred fifty dollars. Unused copies of its successor, the MX510, were selling for even more.
Now, if you were into gaming in the first decade of the 2000s, you may have heard of or used the MX510’s successor, the MX518. Released in 2005, it was basically an MX500/MX510, but branded for gaming, with some optical-sensor upgrades for more tracking precision. The MX518 lasted until 2011, when it was superseded by a different model, which itself was superseded, which et cetera, et cereta, et cetera.
Which brings me to the point of all this. A few weeks ago, after several weeks of sporadic glitches, the scroll wheel on my MX500 almost completely stopped responding to being scrolled. Which maybe doesn’t sound like a big deal, but try going without your scroll wheel for a while. I was surprised to discover how much I relied on it. So, glumly, knowing the model was long out of production and incredibly expensive to buy, I went searching for equivalents.
And that’s when I discovered that Logitech had literally announced less than a week earlier that they were releasing an updated MX518, available for pre-order.
Friends, I have never pre-ordered anything so fast.
This past Thursday afternoon, it arrived. I got it set up and have been working with it since. And I have some impressions.
Physically, the MX518 Legendary (as Logitech has branded it) is 95% a match for my old MX500. It’s ever so slightly smaller, just enough that I can tell but not quite enough to be annoying, odd as that may seem. Otherwise, everything feels like it should. The buttons are crisp and clicky, and right where I expect them. And the scroll wheel… well, it works.
The coloration is different — the surface and buttons are all black, as opposed to the MX500’s black-and-silver two-tone styling. While I miss the two-tone a bit, there’s an upgrade: the smooth black top surface has subtle little sparkles embedded in the paint. Shiny!

On the other hand, configuring the mouse was a bit of an odyssey. First off, let me make clear that I have a weird setup, even for a grumpy old Mac user. I plug a circa-2000 Macally original iKey 104-key keyboard into my 2013 MacBook Pro. (Yes, you have sensed a trend here: when I find hardware I really like, I hang onto it like a rabid weasel. Ditto software.) The “extra” keys on the Macally like Page Up, Home, and so on don’t get recognized by a lot of current software. Even the Finder can’t read the keyboard’s function keys properly. I’ve restored their functionality with the entirely excellent BetterTouchTool, but it remains that the keyboard is just odd in its ancientness.
Anyway, I first opened System Preferences and then the Logitech Control Center pane. It couldn’t find the MX518 Legendary at all. So next I opened the (separate) Logitech Options pane, which drives the wireless mouse I use when I travel. It too was unable to find the MX518.
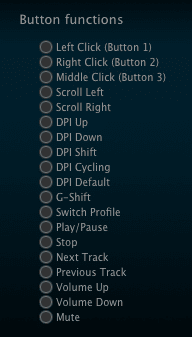
Some Bing-ing led me to a download for Logitech Gaming Software (hereafter LGS), which I installed. That could see the MX518 just fine. Once I stumbled my way into an understanding of LGS’s UI, I set about trying to configure the MX518’s buttons to do what I wanted.
And could not. In the list of predefined mouse actions that could be assigned to the buttons, precisely none of my desires were listed. No ⌘-arrow combos, no page up or down, not even ⌥⇥ to switch apps. I mean, I guess that’s to be expected: it’s sold as a gaming mouse. LGS has plenty of support for on-the-fly-dee-pee-eye switching and copy-paste and all that. Not so much for document editing and code browsing.
There is a way to assign keyboard combos to buttons, but again, the software could understand precisely none of the combos I wanted to record when I typed them on my Macally. So I went to the MacBook Pro’s built-in keyboard, where I was able to register ⌥⇥, ⌘→, and ⌘←. I could not, however much I tried, register Page Up or Page Down. I pressed Fn, which showed “Fn” in the LGS software, and then pressed the down arrow for Page Down, and as long as I held down both keys, it showed “Page Down”. But as soon as I let go of the down arrow, “Fn” was registered again. No Page Down for me.
Now, recall, this was happening on the laptop’s built-in keyboard. I can’t really blame this one on age of the external Macally. I really think this one might fall on LGS itself; while a 2013 MacBook is old, it’s not that old.

I thought I might be stuck, but I intuited a workaround: I opened the Keyboard Viewer app built into the Finder. With that, I could just click the virtual Page Up and Page Down keys, and LGS registered them without a hiccup. While I was in there, I used it to set the scroll wheel’s middle-button click to trigger Mission Control (F3).
The following key-repeat problem has been fixed and was not the fault of the MX518; see my comment for details on how I resolved it. The one letdown I have is that the buttons don’t appear to repeat keystrokes. So if I hold the button I’ve assigned to Page Down for example, I get exactly one page-down, and that’s it until I release and click the button again. On the MX500, holding down the button assigned to Page Down would just constantly page down until I let go. This was sometimes preferable to scrolling with the scroll wheel, especially for long documents I wanted to very quickly scan for a certain figure or other piece of the page. The same was true for all the buttons: hold it down, and the thing it was configured to do happened repeatedly until you let go.
The MX518 Legendary isn’t doing that. I don’t know if this is an inherent limitation of the mouse, its software, my configuration of it, the interaction of software and operating system, or something else entirely. It’s not an issue forty-nine times out of fifty, but that fiftieth time is annoying.
The other annoyance is one of possibly missed potential. The mouse software has, in keeping with its gaming focus, the ability to set up multiple profiles; that way, you can assign unique actions to the buttons on a per-application basis. I set up a couple of profiles to test it out, but LGS is completely opaque about how to make profiles switch automatically when you switch to an app. I’ll look for an answer online, but it’s annoying that the software promises per-app profiles, and then apparently fails to deliver on that promise.
So after all that, am I happy? Yes. It’s essentially my old mouse, except brand new. My heartfelt thanks to Logitech for bringing this workhorse out of retirement. I look forward to a decade or more with it.