Fixing Postcodes
Published 16 years, 7 months pastIn case anyone’s interested, I finally updated the ZIP archive of all the countries and postcodes from the 2008 ALA survey. The two files are sorted like before, but this time leading-zero postcodes haven’t had their leading zeroes stripped by Excel. Oh, Excel.
I have learned way more about Excel’s “helpful” handling of CSV and text imports than I ever wanted to know. The basic drill is, if you want to open a CSV or text file but don’t want Excel to be “helpful”, don’t drop the file onto Excel or double-click the file icon. No no! That would be too easy.
Instead, launch Excel, select “File > Open”, and then select the CSV or text file you want to open in the file browser. Go through the Text Import Wizard carefully:
- Tell Excel that the file is delimited on the first screen. (Or, if it isn’t, then don’t. I bet it is, though.)
- Tell Excel what delimiter you’re using on the second screen.
- Then—this is the crucial bit—on the third Wizard screen, select the columns you don’t want Excel to “help” you with and set them to “Text”. Be careful about setting all the columns as “Text”, though: if you have non-ASCII characters, Excel will “helpfully” replace their contents with octothorpes when you try to export the data later. Such “help”! It’s so “helpful”!
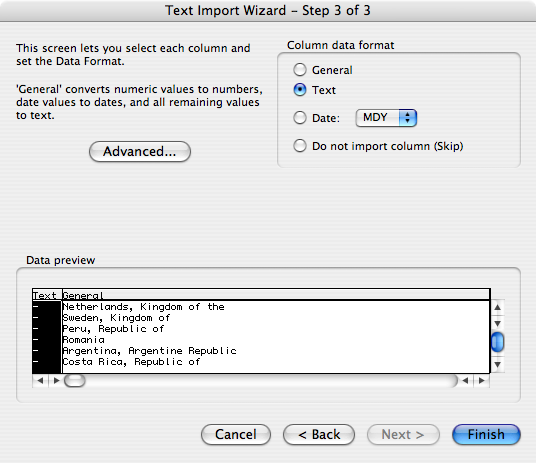
Yay! An open file where the data is all in its original state!
Now you can save the file as an Excel workbook and it should (but please note my use of the word should) leave your data alone. Ditto if you do “Save As…” to export to CSV or text again, which you might do if you run some calculations and want to capture the result in a basic, portable format. But remember! If you ever want to open those CSV/text files in Excel, you can’t just open them. You have to go through the whole text-import process again.
So the survey files now contain actual useful data, especially for countries where postcodes can start with zeroes. (Which is a lot of them.) The files also have the usual bits of abuse that come along with daring to ask people to supply optional information, because I didn’t even try to filter that stuff out. So, you know, naughty words ahead.
In part, I’m posting this to leave a record for anyone else who runs into the same problems I had, and also to remind myself of what has to be done next year. Also to provide a heads-up to anyone who’d like to grab the fixed-up data and do fun mapping stuff with it, as did some commenters on the previous post.
Comments (15)
Why do you have .ar as the “Argentine Republic of Argentina” ?
It’s “Argentina, Argentine Republic”, which (like all the country names) comes the Wikipedia list of countries by continent, which is in turn based on UN and ISO data.
In my experience, OpenOffice Calc is more intuitive when handling CSV, especially when exporting. If I have a spreadsheet that needs to become a database table, I always run it through OOCalc first.
I have to agree with Matthew. OpenOffice Calc is great for dealing with CSV and similar files. It’s the main reason I have it on my system. In fact, all CSV files are associated with OpenOffice Calc so all I have to do is double-click and I’m good to go!
Excel?? OpenOffice Ruuuulezz… =)
And yet, there are tons of people who have to use Excel and use it to open data from other sources, so perhaps this will be of some use to them. Which is, as I said, part of why I posted it.
An easier option is to just open the file in Excel. Then select the column, choose Format Cells and then select the Custom Category.
Enter #0 and then as many additional 0s that you need to precede the numeric.
So where 1 is the cell value, #00 will show 01 and #000 will show 001.
That would be easier, Matt, if I weren’t dealing with a planet’s worth of postcodes. I can’t just assume five digits when some countries use four, some use a mixture of numbers and letters, and some use words with numbers.
Not to mention all the postcode data was hand-entered by survey-takers, so there might be just plain wrong entries, and I don’t want to force-correct them into what might be completely inaccurate values.
So I really did need to open the file without any correction of the data, either by the program or by me.
I found Excel’s ‘helpfulness’ to be maddening as well after having to clean up a client’s mailing list. If you need to do specific manipulation to data in columns or rows that the import wizard cannot handle, set the data to text, select the column or row and copy-paste into BBEdit. In BBEdit you can do grep search and replace to further clean up your data before pasting it back into Excel. Not an elegant solution but it does work.
No sooner had I read this article, acknowledged the problem… and later that very day, was I tasked with helping to solve this very problem! Nicely done ;)
@Chuck: I found that with this zip code data set I was doing a lot of work in my text editor as well. I use TextMate, and the regular expression search and replace was invaluable.
When I worked at the mailshop, we’d always import in Excel — but then we’d toss it over to Visual FoxPro, where we had all our manipulation routines. It became so second-nature to do the import without losing the leading zeros that I can’t even tell you at this point how we did it. :-)
…and if we’re talking text editors, how come nobody’s mentioned Notepad++ yet?
*answers own dumb question*
Ah, right, not all the world runs on Windows.
*headdesk*
Would the handling of the file be any different if the postal code data was wrapped in quotes, just like the text data? I’d presume that Excel would assume it text in that case. But you know what happens when you assume…