Web Page, Mutated
Published 20 years, 8 months pastOne of the first rules of life is that first-hand information is always better than second-hand information. You can be more certain of something if you’ve seen it with your own eyes. Anything else is hearsay, rumor, conjecture—an article of faith, if you will. At the very minimum, you have to have faith that your source is reliable. The problems begin when sources aren’t reliable.
No, this isn’t a rant about the intelligence screw-ups previous to the invasion of Iraq. Instead, it’s a warning that inspector programs and saving as “Web page, complete” features can lead you astray.
One such example came up recently, shortly after I mentioned the launch of the new Technorati design. A question came in:
I did want to ask about the use of
-x-background-{x,y}-positionas opposed tobackground-position. If I understand correctly, the-xprefix indicates an experimental CSS attribute, so in what circumstances should one use this sort of experimental attribute instead of an official one?
I’d have been glad to answer the question, if only I’d known what the heck he was talking about. Those certainly weren’t properties I’d added to the style sheets. They weren’t even properties I’d ever heard of, proprietary or otherwise.
Just to be sure, I loaded the CSS files found on the Technorati site into my browser and searched them for the reported properties. No results. I inquired as to where the reporter had seen them, and it turned out they were showing up in Firefox’s DOM Inspector.
Now, the DOM Inspector is an incredibly useful tool. You can use it to look at the document tree after scripts have run and dynamically added content. You can get the absolute (that is, root-relative) X and Y coordinates of the top left corner of every element, as well as its computed dimensions in pixels. You can see the CSS rules that apply to a given element… not just the everyday CSS properties, but the stuff that the Gecko engine maintains internally.
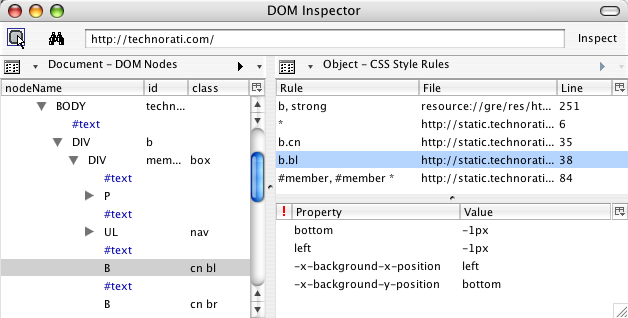
That’s where the problem had come in. The DOM Inspector was showing special property names, splitting the background-position values into two different pseudo-properties, and not showing the actual background-position declaration. This, to me, is a flaw in the Inspector. It should do two things differently:
- It should show the declaration found in the style sheet. There should be a line that shows
background-positionandbottom left(or whatever), because that’s what the style sheet contains. - It should present the internally-computed information differently than the stuff actually taken from the style sheet. One possibility would be to show any internal property/value pair as gray italicized text. I’d also like an option to suppress display of the internal information, so that all I see is what the style sheet contains.
The person who asked why I was using those properties wasn’t stupid. He was just unaware that his tool was giving him a distorted picture of the style sheet’s contents.
Don’t think Firefox is the only culprit in unreliable reporting, though. Anyone who uses Internet Explorer’s save as “Web page, complete” feature to create a local copy for testing purposes isn’t getting an actual copy. Instead of receiving local mirrors of the files found on the Web server, they’re getting a dump from the browser’s internals. So an external style sheet will actually be what the browser computed, not what the author wrote. For example, this:
body {margin: 0; padding: 0;
background: white url(bodybg.gif) 0 0 no-repeat; color: black;
font: small Verdana, Arial, sans-serif;}
…becomes this:
BODY {
PADDING-RIGHT: 0px; PADDING-LEFT: 0px;
BACKGROUND: url(bodybg.gif) white no-repeat 0px 0px;
PADDING-BOTTOM: 0px; MARGIN: 0px; FONT: small Verdana, Arial, sans-serif;
COLOR: black; PADDING-TOP: 0px
}
Okay, so it destroys the authoring style, but it isn’t like it actually breaks anything, right? Wrong. For some reason, despite IE treating the universal selector correctly, any rule that employs a universal selector will lose the universal selector when it’s saved as “Web page, complete”. Thus, this:
#sidebar {margin: 0 74% 3em 35px; padding: 0;}
#sidebar * {margin: 0; padding: 0;}
…becomes this:
#sidebar {
PADDING-RIGHT: 0px; PADDING-LEFT: 0px; PADDING-BOTTOM: 0px;
MARGIN: 0px 74% 3em 35px; PADDING-TOP: 0px
}
#sidebar {
PADDING-RIGHT: 0px; PADDING-LEFT: 0px; PADDING-BOTTOM: 0px;
MARGIN: 0px; PADDING-TOP: 0px
}
Oops. Not only can this mean the local copy renders very differently as compared to the “live” version, it’s also very confusing for anyone who’s saved the page in order to learn from it. Why in the world would anyone write two rules in a row with the same selector? Answer: nobody would. Your tool simply fooled you into thinking that someone did.
Incidentally, if you want to see the IE-mangled examples I showed in a real live set of files on your hard drive, go save as “Web page, complete” the home page of Complex Spiral Consulting using IE/Win. And from now on, I’ll always put “Web page, complete” in quotes because it’s an inaccurate label. It should really say that IE will save as “Web page, mutated”.
So if you’re Inspecting a page, or viewing a saved copy, remember this: nothing beats seeing the original, actual source with your own eyes. If you see something odd in your local copy, your first step should be to go to the original source and make sure the oddness is really there, and not an artifact of your tools.
Comments (23)
In a similar vein, I once learned the hard way that Interarchy’s “Download Entire Site…” command doesn’t download stylesheets linked using the @import method.
Ultimately, it was my fault that I didn’t check it after I’d downloaded it, but that didn’t save me from looking bad when I loaded an unstyled website on my laptop away from a network connection.
Given your latest posting, it makes me nervous that “View Page Source” in Firefox doesn’t actually show you the true source, either — in fact I’m pretty sure it shows you characters instead of their entities (for example).
I was trying to track down a character encoding problem that a colleague was experiencing the other day. She visited a site with Swedish text, but all the å’s, ä’s and ö’s were shown as question marks. I used View/Page Info to see the encoding, and it said UTF-8. The page was clearly ISO8859-1, which explained why it looked weird.
But then I checked the page with Opera’s Info panel, and discovered that the server didn’t send any encoding information at all. Firefox wasn’t showing us what the server sent, but what the browser had guessed. Sneaky! I’m glad we figured it out before sending a smug email to the company complaining about serving the wrong encoding information.
My Gosh. Who thinks of this? I can only think of a handful of times I’ve used the universal rule (*) being applied to a nested element, and then having to ‘save web page as’ on it.
All I can say is, good catch! This goes under the category of “I never would have noticed – but would have been frustrated for hours!”
I’d agree it is folly to always rely upon the saved document I’ve seen such things quite a lot of times when saving with various browsers and I don’t just mean using; complete webpage download option.
The DOM inspector is doing what I want it to—it’s a DOM inspector, not a document inspector. I can always inspect the source document using view-source or tools like wget or cURL. If Firefox is doing something strange to my page, I need to see what it thinks I’m telling it to do, not what I think I’m telling it to do.
I discovered IE’s strange “save as web page, complete” behavior back when I was using it as my browser . Once I understood what it was doing (dumping the parsed DOM, not the original document), I used it as a primative DOM inspector (if I used it at all). One happy discovery about the CSS it saves—it only folds the names of properties it recognizes; names of CSS properties it doesn’t support are left in lower case.
The DOM inspector doesn’t really present computed values in the rule view, that’s what the computed view is for. In the rule view, it appears to present split values, that is, lengthening various shorthands into their individual properties. And under CSS3, background-position is indeed just a shorthand for background-x-position and background-y-position, which thus get presented in the rule view. (As the experimental -x-prefixed versions that Mozilla currently implements.)
Which isn’t to say that it isn’t wrong to do so.
However, I disagree with you what it should do. It should just present the style rules as they appear in the style sheet itself. Nothing more, nothing less. Splitting properties is of no use.
There already is the “Computed Style” section of the node properties. Use this one if you care for the split properties.
Oh, and I forgot to say: I do hope you reported this as a bug, or discovered an existing report about it. Would you perhaps share the Bug#?
this is also what you have to deal with when using visual editing mode on either browser. Regardless of the CSS (or HTML for that matter) you put into a visual editing input field in IE, you’ll get the split-apart shortcut rules, capital letters, etc etc. mozilla does it too, of course, just not quite as blantantly. fun stuff.
I completely agree with Steve Fulton: the DOM Inspector should (and does) show what the browser is doing, not what was originally said. After all, it would be pretty useless if it showed you the exact same thing as “view source”, wouldn’t it?
@mike: I’m not sure exactly what you mean, but html by definition has capital letters for tag names in the DOM and various other rules that you’re probably seeing. It’s entirely likely that IE and maybe gecko have bugs, though.
I’ve been bitten by this before; Firefox decided that it wanted to wrap some
tables in atbodyelement, which did wonders for a.) breaking some child selectors I’d been writing and b.) making me tear my hair out by the fistfuls.Huzzah for browsers. They’re the best.
Hm, perhaps you’re right, Sebastian:
…although I would still want a preference to show or suppress the split/computed/whatever rules in the CSS Style Rules view, as long as they were differently presented. Being able to see both declared and computed styles in one place would be more useful (to me, anyway) than splitting them into two entirely separate views.
Ethan: I suspect Firefox was actually wrapping all the rows of each of your tables in a
tbodyelement, not wrapping a bunch of tables in onetbodyelement. Correct?Tangentially related, I’ve lately been using a great inspector called Xylescope, which breaks down the CSS and HTML and uses WebKit to display pages.
You wouldn’t believe (or would you?) the number of Zen Garden submissions I get which have started their life as saved source from Win/IE. THE ALL CAPS HTML KIND OF GIVES IT AWAY, PEOPLE.
From a CSS perspective, none of them seem to have suffered for this since they appear to render properly. Which I continually find surprising.
Oh, and while I’m here… make that a second vote for Xylescope. Totally worth the $15.
Ack. Eric, you’re right, of course—thanks for clarifying.
Ethan no speak good caffeine without.
Browser’s have long been know to mangle the content of documents with any attempt to save the complete web page, including Mozilla. It’s not uncommon that saving a perfectly valid web page (particularly an XHTML document served as text/html) will not remain either valid or well formed. Although i wasn’t aware of IE mangling the stylesheet too, I never rely on any form of “save as web page, complete” in any browser.
Pingback ::
JeffHung.Blog » 今日連結 (2005-07-10)
[…] 還不如說誠實和負責,我覺得那才是blogger的信任來源。 Web Page, Mutated – 所以說,Mail Archive Format 每次都去重新抓網頁, […]
If you use external style sheets with @import, this breaks the whole “Save Webpage, complete” thing in IE/Win. IE stops with a message like “Could not save web page”. Ugh!
Klaus, you can consider yourself lucky if you get the error message. I have seen cases where doing a “Save Webpage, complete” on a page that has a link rel to a style sheet in which another CSS is imported via @import sends IE/Win into a death spiral.
Just a thought I had and didn’t see in any of the comments but why not send the webpage you are trying to view the css code on through the css validator at http://www.w3.org?
DOM inpector can be better
2Dimitriy:
Why is that? I’ve used DOM Inspector and can’t see any advantages…
Pingback ::
今日連結 (2005-07-10) [JeffHung.Blog]
[…] Web Page, Mutated – 所以說,Mail Archive Format 每次都去重新抓網頁,應該是會產生真的 “Web page, complete” 的囉? […]