A few days ago was the 30th anniversary of the first time I wrote an HTML document. Back in 1993, I took a Usenet posting of the “Incomplete Mystery Science Theater 3000 Episode Guide” and marked it up. You can see the archived copy here on meyerweb. At some point, the markup got updated for reasons I don’t remember, but I can guarantee you the original had uppercase tag names and I didn’t close any paragraphs. That’s because I was using <P> as a shorthand for <BR><BR>, which was the style at the time.
Its last-updated date of December 3, 1993, is also the date I created it. I was on lobby duty with the CWRU Film Society, and had lugged a laptop (I think it was an Apple PowerBook of some variety, something like a 180, borrowed from my workplace) and a printout of the HTML specification (or maybe it was “Tags in HTML”?) along with me.
I spent most of that evening in the lobby of Strosacker Auditorium, typing tags and doing find-and-replace operations in Microsoft Word, and then saving as text to a file that ended in .html, which was the style at the time. By the end of the night, I had more or less what you see in the archived copy.
The only visual change between then and now is that a year or two later, when I put the file up in my home directory, I added the toolbars at the top and bottom of the page — toolbars I’d designed and made a layout standard as CWRU’s webmaster. Which itself only happened because I learned HTML.
A couple of years ago, I was fortunate enough to be able to relate some of this story to Joel Hodgson himself. The story delighted him, which delighted me, because delighting someone who has been a longtime hero really is one of life’s great joys. And the fact that I got to have that conversation, to feel that joy, is inextricably rooted in my sitting in that lobby with that laptop and that printout and that Usenet post, adding tags and saving as text and hitting reload in Mosaic to instantly see the web page take shape, thirty years ago this week.
In my previous post, I wrote about a way to center elements based on their content, without forcing the element to be a specific width, while preserving the interior text alignment. In this post, I’d like to talk about why I developed that technique.
Near the beginning of this year, fellow Web nerd and nuclear history buff Chris Griffith mentioned a project to put an entire book online: The Effects of Nuclear Weapons by Samuel Glasstone and Philip J. Dolan, specifically the third (1977) edition. Like Chris, I own a physical copy of this book, and in fact, the information and tools therein were critical to the creation of HYDEsim, way back in the Aughts. I acquired it while in pursuit of my degree in History, for which I studied the Cold War and the policy effects of the nuclear arms race, from the first bombers to the Strategic Defense Initiative.
I was immediately intrigued by the idea and volunteered my technical services, which Chris accepted. So we started taking the OCR output of a PDF scan of the book, cleaning up the myriad errors, re-typing the bits the OCR mangled too badly to just clean up, structuring it all with HTML, converting figures to PNGs and photos to JPGs, and styling the whole thing for publication, working after hours and in odd down times to bring this historical document to the Web in a widely accessible form. The result of all that work is now online.
That linked page is the best example of the technique I wrote about in the aforementioned previous post: as a Table of Contents, none of the lines actually get long enough to wrap. Rather than figuring out the exact length of the longest line and centering based on that, I just let CSS do the work for me.
There were a number of other things I invented (probably re-invented) as we progressed. Footnotes appear at the bottom of pages when the footnote number is activated through the use of the :target pseudo-class and some fixed positioning. It’s not completely where I wanted it to be, but I think the rest will require JS to pull off, and my aim was to keep the scripting to an absolute minimum.
LaTeX and MathJax made writing and rendering this sort of thing very easy.
I couldn’t keep the scripting to zero, because we decided early on to use MathJax for the many formulas and other mathematical expressions found throughout the text. I’d never written LaTeX before, and was very quickly impressed by how compact and yet powerful the syntax is.
Over time, I do hope to replace the MathJax-parsed LaTeX with raw MathML for both accessibility and project-weight reasons, but as of this writing, Chromium lacks even halfway-decent MathML support, so we went with the more widely-supported solution. (My colleague Frédéric Wang at Igalia is pushing hard to fix this sorry state of affairs in Chromium, so I do have hopes for a migration to MathML… some day.)
The figures (as distinct from the photos) throughout the text presented an interesting challenge. To look at them, you’d think SVG would be the ideal image format. Had they come as vector images, I’d agree, but they’re raster scans. I tried recreating one or two in hand-crafted SVG and quickly determined the effort to create each was significant, and really only worked for the figures that weren’t charts, graphs, or other presentations of data. For anything that was a chart or graph, the risk of introducing inaccuracies was too high, and again, each would have required an inordinate amount of effort to get even close to correct. That’s particularly true considering that without knowing what font face was being used for the text labels in the figures, they’d have to be recreated with paths or polygons or whatever, driving the cost-to-recreate astronomically higher.
So I made the figures PNGs that are mostly transparent, except for the places where there was ink on the paper. After any necessary straightening and some imperfection cleanup in Acorn, I then ran the PNGs through the color-index optimization process I wrote about back in 2020, which got them down to an average of 75 kilobytes each, ranging from 443KB down to 7KB.
At the 11th hour, still secretly hoping for a magic win, I ran them all through svgco.de to see if we could get automated savings. Of the 161 figures, exactly eight of them were made smaller, which is not a huge surprise, given the source material. So, I saved those eight for possible future updates and plowed ahead with the optimized PNGs. Will I return to this again in the future? Probably. It bugs me that the figures could be better, and yet aren’t.
It also bugs me that we didn’t get all of the figures and photos fully described in alt text. I did write up alternative text for the figures in Chapter I, and a few of the photos have semi-decent captions, but this was something we didn’t see all the way through, and like I say, that bugs me. If it also bugs you, please feel free to fork the repository and submit a pull request with good alt text. Or, if you prefer, you could open an issue and include your suggested alt text that way. By the image, by the section, by the chapter: whatever you can contribute would be appreciated.
Those image captions, by the way? In the printed text, they’re laid out as a label (e.g., “Figure 1.02”) and then the caption text follows. But when the text wraps, it doesn’t wrap below the label. Instead, it wraps in its own self-contained block instead, with the text fully justified except for the last line, which is centered. Centered! So I set up the markup and CSS like this:
<figure>
<img src="…" alt="…" loading="lazy">
<figcaption>
<span>Figure 1.02.</span> <span>Effects of a nuclear explosion.</span>
</figcaption>
</figure>
Oh CSS Grid, how I adore thee. And you too, CSS box alignment. You made this little bit of historical recreation so easy, it felt like cheating.
Look at the way it’s all supposed to line up on the ± and one number doesn’t even have a ± and that decimal is just hanging out there in space like it’s no big deal. LOOK AT IT.
Some other things weren’t easy. The data tables, for example, have a tendency to align columns on the decimal place, even when most but not all of the numbers are integers. Long, long ago, it was proposed that text-align be allowed a string value, something like text-align: '.', which you could then apply to a table column and have everything line up on that character. For a variety of reasons, this was never implemented, a fact which frosts my windows to this day. In general, I mean, though particularly so for this project. The lack of it made keeping the presentation historically accurate a right pain, one I may get around to writing about, if I ever overcome my shame. [Editor’s note: he overcame that shame.]
There are two things about the book that we deliberately chose not to faithfully recreate. The first is the font face. My best guess is that the book was typeset using something from the Century family, possibly Century Schoolbook (the New version of which was a particular favorite of mine in college). The very-widely-installed Cambria seems fairly similar, at least to my admittedly untrained eye, and furthermore was designed specifically for screen media, so I went with body text styling no more complicated than this:
body {
font: 1em/1.35 Cambria, Times, serif;
hyphens: auto;
}
I suppose I could have tracked down a free version of Century and used it as a custom font, but I couldn’t justify the performance cost in both download and rendering speed to myself and any future readers. And the result really did seem close enough to the original to accept.
The second thing we didn’t recreate is the printed-page layout, which is two-column. That sort of layout can work very well on the book page; it almost always stinks on a Web page. Thus, the content of the book is rendered online in a single column. The exceptions are the chapter-ending Bibliography sections and the book’s Index, both of which contain content compact and granular enough that we could get away with the original layout.
There’s a lot more I could say about how this style or that pattern came about, and maybe someday I will, but for now let me leave you with this: all these decisions are subject to change, and open to input. If you come up with a superior markup scheme for any of the bits of the book, we’re happy to look at pull requests or issues, and to act on them. It is, as we say in our preface to the online edition, a living project.
We also hope that, by laying bare the grim reality of these horrific weapons, we can contribute in some small way to making them a dead and buried technology.
After my post the other day about how I got started with CSS 25 years ago, I found myself reflecting on just how far CSS itself has come over all those years. We went from a multi-year agony of incompatible layout models to the tipping point of April 2017, when four major Grid implementations shipped in as many weeks, and were very nearly 100% consistent with each other. I expressed delight and astonishment at the time, but it still, to this day, amazes me. Because that’s not what it was like when I started out. At all.
I know it’s still fashionable to complain about how CSS is all janky and weird and unapproachable, but child, the wrinkles of today are a sunny park stroll compared to the jagged icebound cliff we faced at the dawn of CSS. Just a few examples, from waaaaay back in the day:
In the initial CSS implementation by Netscape Navigator 4, padding was sometimes a void. What I mean is, you could give an element a background color, and you could set a border, but if you adding any padding, in some situations it wouldn’t take on the background color, allowing the background of the parent element to show through. Today, we can recreate that effect like so:
But we didn’t havebackground-clip in those days, and backgrounds weren’t supposed to act like that. It was just a bug that got fixed a few versions later. (It was easier to get browsers to fix bugs in those days, because the web was a lot smaller, and so were the stakes.) Until that happened, if you wanted a box with border, background, padding, and content in Navigator, you wrapped a <div> inside another <div>, then applied the border and background to the outer and the padding (or a margin, at that point it didn’t matter) to the inner.
In another early Navigator 4 version, pica math was inverted: Instead of 12 points per pica, it was set to 12 picas per point — so 12pt equated to 144pc instead of 1pc. Oops.
Navigator 4’s handling of color values was another fun bit of bizarreness. It would try to parse any string as if it were hexadecimal, but it did so in this weird way that meant if you declared color: inherit it would render in, as one person put it, “monkey-vomit green”.
Internet Explorer for Windows started out by only tiling background images down and to the right. Which was fine if you left the origin image in the top left corner, but as soon as you moved it with background-position, the top and left sides of the element just… wouldn’t have any background. Sort of like Navigator’s padding void!
At one point, IE/Win (as we called it then) just flat out refused to implement background-position: fixed. I asked someone on that team point blank if they’d ever do it, and got just laughter and then, “Ah no.” (Eventually they relented, opening the door for me to create complexspiral and complexspiral distorted.)
For that matter, IE/Win didn’t inherit font sizes into tables. Which would be annoying even today, but in the era of still needing tables to do page-level layout, it was a real problem.
IE/Win had so many layout bugs, there were whole sites dedicated to cataloging and explaining them. Some readers will remember, and probably shudder to do so, the Three-Pixel Text Jog, the Phantom Box Bug, the Peekaboo Bug, and more. Or, for that matter, hasLayout/zoom.
And perhaps most famous of all, Netscape and Opera implemented the W3C box model (2021 equivalent: box-sizing: content-box) while Microsoft implemented an alternative model (2021 equivalent: box-sizing: border-box), which meant apparently simple CSS meant to size elements would yield different results in different browsers. Possibly vastly different, depending on the size of the padding and so on. Which model is more sensible or intuitive doesn’t actually matter here: the inconsistency literally threatened the survival of CSS itself. Neither side was willing to change to match the other — “we have customers!” was the cry — and nobody could agree on a set of new properties to replace height and width. It took the invention of DOCTYPE switching to rescue CSS from the deadlock, which in turn helped set the stage for layout-behavior properties like box-sizing.
I could go on. I didn’t even touch on Opera’s bugs, for example. There was just so much that was wrong. Enough so that in a fantastic bit of code aikido, Tantek turned browsers’ parsing bugs against them, redirecting those failures into ways to conditionally deliver specific CSS rules to the browsers that needed them. A non-JS, non-DOCTYPE form of browser sniffing, if you like — one of the earliest progenitors of feature queries.
I said DOCTYPE switching saved CSS, and that’s true, but it’s not the whole truth. So did the Web Standards Project, WaSP for short. A group of volunteers, sick of the chaotic landscape of browser incompatibilities (some intentional) and the extra time and cost of dealing with them, who made the case to developers, browser makers, and the tech press that there was a better way, one where browsers were compatible on the basics like W3C specifications, and could compete on other features. It was a long, wearying, sometimes frustrating, often derided campaign, but it worked.
The state of the web today, with its vast capability and wide compatibility, owes a great deal to the WaSP and its allies within browser teams. I remember the time that someone working on a browser — I won’t say which one, or who it was — called me to discuss the way the WaSP was treating their browser. “I want you to be tougher on us,” they said, surprising the hell out of me. “If we can point to outside groups taking us to task for falling short, we can make the case internally to get more resources.” That was when I fully grasped that corporations aren’t monoliths, and formulated my version of Hanlon’s Razor: “Never ascribe to malice that which is adequately explained by resource constraints.”
The original Acid Test.
In order to back up what we said when we took browsers to task, we needed test cases. This not only gave the CSS1 Test Suite a place of importance, but also the tests the WaSP’s CSS Action Committee (aka the CSS Samurai) devised. The most famous of these is the first CSS Acid Test, which was added to the CSS1 Test Suite and was even used as an Easter egg in Internet Explorer 5 for Macintosh.
The need for testing, whether acid or basic, lives on in the Web Platform Tests, or WPT for short. These tests form a vital link in the development of the web. They allow specification authors to create reference results for the rules in those specifications, and they allow browser makers to see if the code they’re writing yields the correct results. Sometimes, an implementation fails a test and the implementor can’t figure out why, which leads to a discussion with the authors of the specification, and that can lead to clarifications of the specification, or to fixing flawed tests, or even to both. Realize just how harmonious browser support for HTML and CSS is these days, and know that WPT deserves a big part of the credit for that harmony.
As much as the Web Standards Project set us on the right path, the Web Platform Tests keep us on that path. And I can’t lie, I feel like the WPT is to the CSS1 Test Suite much like feature queries are to those old CSS parser hacks. The latter are much greater and more powerful than than the former, but there’s an evolutionary line that connects them. Forerunners and inheritors. Ancestors and descendants.
It’s been a real privilege to be present as CSS first emerged, to watch as it’s developed into the powerhouse it is today, and to be a part of that story — a story that is, I believe, far from over. There are still many ways for CSS to develop, and still so many things we have yet to discover in its feature set. It’s still an entrancing language, and I hope I get to be entranced for another 25 years.
It was the morning of Tuesday, May 7th and I was sitting in the Ambroisie conference room of the CNIT in Paris, France having my mind repeatedly blown by an up-and-coming web technology called “Cascading Style Sheets”, 25 years ago this month.
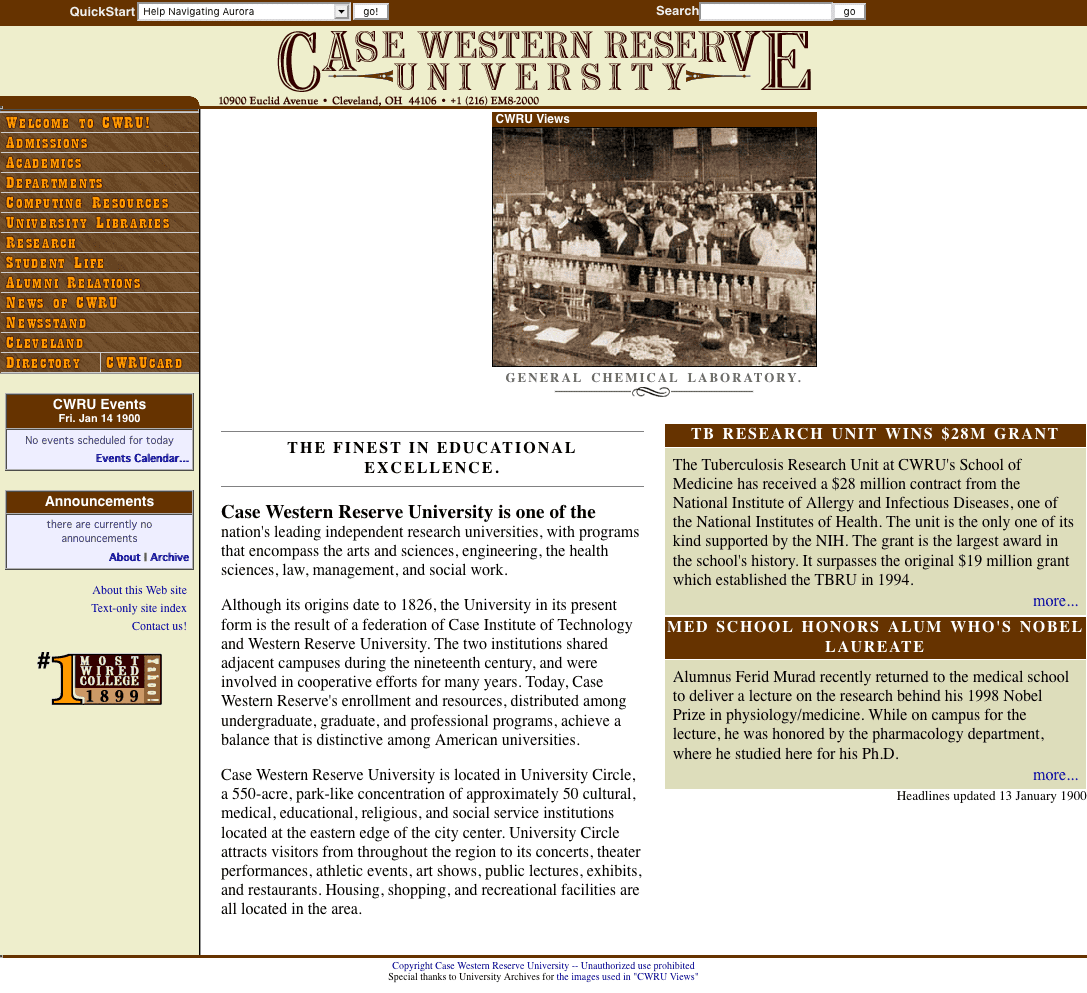
I’d been the Webmaster at Case Western Reserve University for just over two years at that point, and although I was aware of table-driven layout, I’d resisted using it for the main campus site. All those table tags just felt… wrong. Icky. And yet, I could readily see how not using tables hampered my layout options. I’d been holding out for something better, but increasingly unsure how much longer I could wait.
Having successfully talked the university into paying my way to Paris to attend WWW5, partly by having a paper accepted for presentation, I was now sitting in the W3C track of the conference, seeing examples of CSS working in a browser, and it just felt… right. When I saw a single word turned a rich blue and 100-point size with just a single element and a few simple rules, I was utterly hooked. I still remember the buzzing tingle of excitement that encircled my head as I felt like I was seeing a real shift in the web’s power, a major leap forward, and exactly what I’d been holding out for.
Page 4, HTML 3.2.
Looking back at my hand-written notes (laptops were heavy, bulky, battery-poor, and expensive in those days, so I didn’t bother taking one with me) from the conference, which I still have, I find a lot that interests me. HTTP 1.1 and HTML 3.2 were announced, or at least explained in detail, at that conference. I took several notes on the brand-new <OBJECT> element and wrote “CENTER is in!”, which I think was an expression of excitement. Ah, to be so young and foolish again.
There are other tidbits: a claim that “standards will trail innovation” — something that I feel has really only happened in the past decade or so — and that “Math has moved to ActiveMath”, the latter of which is a term I freely admit I not only forgot, but still can’t recall in any way whatsoever.
My first impressions of CSS, split for no clear reason across two pages.
But I did record that CSS had about 35 properties, and that you could associate it with markup using <LINK REL=STYLESHEET>, <STYLE>…</STYLE>, or <H1 STYLE="…">. There’s a question — “Gradient backgrounds?” — that I can’t remember any longer if it was a note to myself to check later, or something that was floated as a possibility during the talk. I did take notes on image backgrounds, text spacing, indents (which I managed to misspell), and more.
What I didn’t know at the time was that CSS was still largely vaporware. Implementations were coming, sure, but the demos I’d seen were very narrowly chosen and browser support was minimal at best, not to mention wildly inconsistent. I didn’t discover any of this until I got back home and started experimenting with the language. With a printed copy of the CSS1 specification next to me, I kept trying things that seemed like they should work, and they didn’t. It didn’t matter if I was using the market-dominating behemoth that was Netscape Navigator or the scrappy, fringe-niche new kid Internet Explorer: very little seemed to line up with the specification, and almost nothing worked consistently across the browsers.
So I started creating little test pages, tackling a single property on each page with one test per value (or value type), each just a simple assertion of what should be rendered along with a copy of the CSS used on the page. Over time, my completionist streak drove me to expand this smattering of tests to cover everything in CSS1, and the perfectionist in me put in the effort to make it easy to navigate. That way, when a new browser version came out, I could run it through the whole suite of tests and see what had changed and make note of it.
Eventually, those tests became the CSS1 Test Suite, and the way it looks today is pretty much how I built it. Some tests were expanded, revised, and added, plus it eventually all got poured into a basic test harness that I think someone else wrote, but most of the tests — and the overall visual design — were my work, color-blindness insensitivity and all. Those tests are basically what got me into the Working Group as an Invited Expert, way back in the day.
Before that happened, though, with all those tests in hand, I was able to compile CSS browser support information into a big color-coded table, which I published on the CWRU web site (remember, I was Webmaster) and made freely available to all. The support data was stored in a large FileMaker Pro database, with custom dropdown fields to enter the Y/N/P/B values and lots of fields for me to enter template fragments so that I could export to HTML. That support chart eventually migrated to the late Web Review, where it came to be known as “the Mastergrid”, a term I find funny in retrospect because grid layout was still two decades in the future, and anyway, it was just a large and heavily styled data table. Because I wasn’t against tables for tabular data. I just didn’t like the idea of using them solely for layout purposes.
And it all kicked off 25 years ago this month in a conference room in Paris, May 7th, 1996. What a journey it’s been. I wonder now, in the latter half of my life, what CSS — what the web itself — will look like in another 25 years.
Before I tell you this story of January 1st, 2000, I need to back things up a few months into mid-1999. I was working at Case Western Reserve University as a Hypermedia Systems Specialist, which was the closest the university’s job title patterns could get to my actual job which was, no irony or shade, campus Webmaster. I was in charge of www.cwru.edu and providing support to departments who wanted a Web presence on our server, among many other things. My fellow Digital Media Services employees provided similar support for other library and university systems.
So in mid-1999, we were deep in the throes of Y2K certification. The young’uns in the audience won’t remember this, but to avoid loss of data and services when the year rolled from 1999 to 2000, pretty much the entire computer industry was engaged in a deep audit of every computer and program under our care. There’s really been nothing quite like it, before or since, but the job got done. In fact, it got done so well, barely anything adverse happened and some misguided people now think it was all a hoax designed to extract hefty consulting fees, instead of the successful global preventative effort it actually was.
As for us, pretty much everything on the Web side was fine. And then, in the middle of one of our staff meetings about Y2K certification, John Sully said something to the effect of, “Wouldn’t it be funny if the Web server suddenly thought it was 1900 and you had to use a telegraph to connect to it?”
We all laughed and riffed on the concept for a bit and then went back to Serious Work Topics, but the idea stuck in my head. What would a 1900-era Web site look like? Technology issues aside, it wasn’t a complete paradox: the ancestor parts of CWRU, the Case Institute of Technology and the Western Reserve University, had long existed by 1900 (founded 1880 and 1826, respectively). The campus photos would be black and white rather than color, but there would still be photos. The visual aesthetic might be different, but…
I decided so make it a reality, and CWRU2K was born. With the help of the staff at University Archives and a flatbed scanner I hauled across campus on a loading dolly, I scanned a couple dozen photos from the period 1897-1900 — basically, all those that were known to be in the public domain, and which depicted the kinds of scenes you might put on a Web site’s home page.
Then I reskinned the home page to look more “old-timey” without completely altering the layout or look. Instead of university-logo blues and gold, I recolored everything to be wood-grain. Helvetica was replaced with an “Old West” font in the images, of which there were several, mostly in the form of MM_swapimage-style rollover buttons. In the process, I actually had to introduce two Y2K bugs to the code we used to generate dates on the page, so that instead of saying 2000 they’d actually say 1899 or 1900. I altered other things to match the time, like altering the phone number to use two-letters-then-numbers format while still retaining full international dialing information and adding little curlicues to things. Well before the holidays, everything was ready.
The files were staged, a cron job was set up, and at midnight on January 1st, 2000, the home page seamlessly switched over to its 1900 incarnation. That’s a static snapshot of the page, so the picture will never change, but I have a gallery of all the pictures that could appear, along with their captions, which I strove to write in that deadpan stating-the-obvious tone the late 19th Century always brings to my mind. (And take a close look at the team photo of The Rough Riders!)
In hindsight, our mistake was most likely in adding a similarly deadpan note to the home page that read:
Year 2000 Issues
Despite our best efforts at averting Y2K problems, it seems that our Web server now believes that it is January of 1900. Please be advised that we are working diligently on the problem and hope to have it fixed soon.
I say that was a mistake because it was quoted verbatim in stories at Wired and The Washington Post about Y2K glitches. Where they said we’d actually suffered a real, unintentional Y2K bug, with Wired giving us points for having “guts” in publicly calling “a glitch a glitch”. After I emailed both reporters to explain the situation and point them to our press release about it, The Washington Post did publish a correction a few days later, buried in a bottom corner of page A16 or something like that. So far as I know, Wired never acknowledged the error.
CWRU2K lasted a little more than a day. Although we’d planned to leave it up until the end of January, we were ordered to take it down on January 2nd. My boss, Ron Ryan, was directed to put a note in my Permanent Record. The general attitude Ron conveyed to me was along the lines of, “The administration says it’s clever and all, but it’s time to go back to the regular home page. Next time, we need to ask permission rather than forgiveness.”
What we didn’t know at the time was how close he’d come to being fired. At Ron’s retirement party last year, the guy who was his boss on January 2nd, 2000, Jim Barker, told Ron that Jim had been summoned that day to a Vice President’s office, read the riot act, and was sent away with instructions to “fire Ron’s ass”. Fortunately, Jim… didn’t. And then kept it to himself for almost 20 years.
There were a number of other consequences. We got a quite a bit of email about it, some in on the joke, others taking it as seriously as Wired. There’s a particularly lovely note partway down that page from the widow of a Professor Emeritus, and have to admit that I still smile over the props we got from folks on the NANOG mailing list. I took an offer to join a startup a couple of months later, and while I was probably ready to move on in any case, the CWRU2K episode — or rather, the administration’s reaction to it — helped push me to make the jump. I was probably being a little juvenile and over-reacting, but I guess you do that when you’re younger. (And I probably would have left the next year regardless, when I got the offer to join Netscape as a Standards Evangelist. Actual job title!)
So, that’s the story of how Y2K affected me. There are some things I probably would have done differently if I had it to do over, but I’m 100% glad we did it.
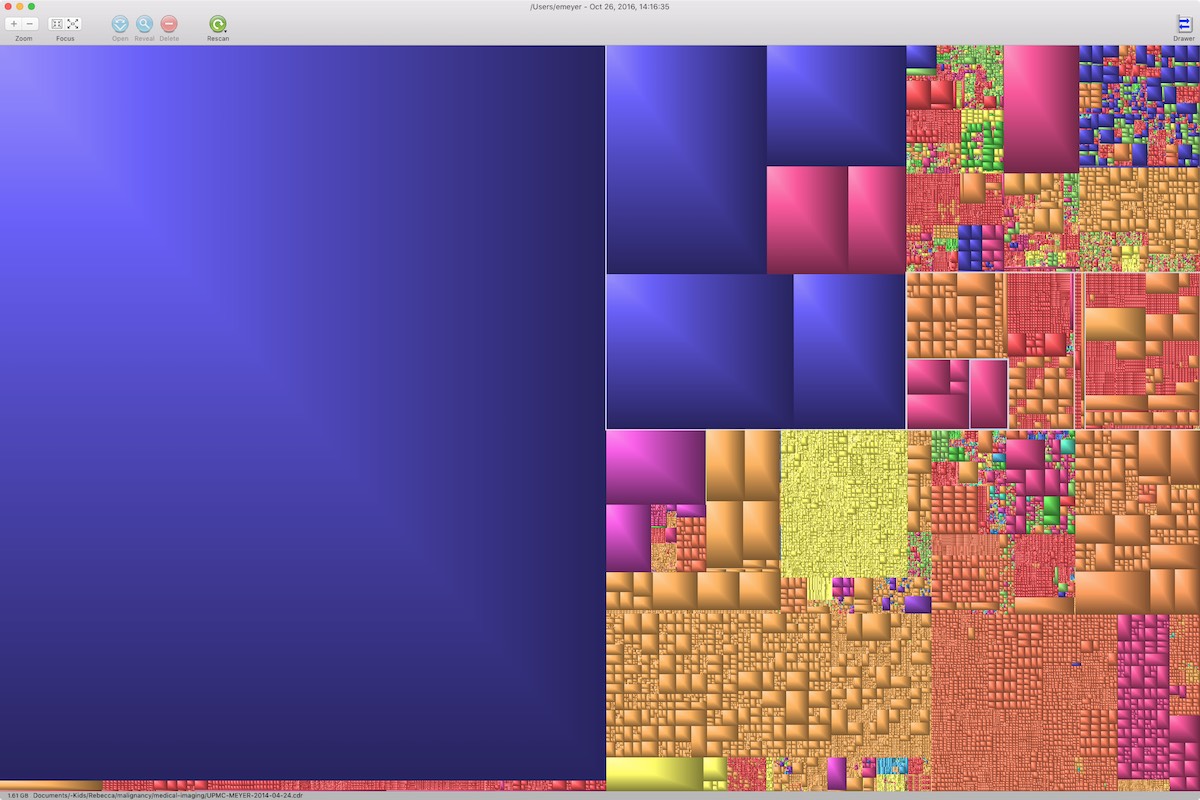
I sat digging through the map built by GrandPerspective, showing me what was chewing up 720GB of my 750GB SSD. I already knew my iPhoto Library was the main culprit, consuming just over a third of the total volume, but surely there were other places I was wasting space. And there were: old software installers, virtual machines I had long since ceased to need, movies I’d ripped for watching on trips and never gotten around to dumping afterward, years-old Keynote files that I’d never gotten around to compressing. I dealt with the most obvious offenders, one way or another, and then rescanned the volume.
A set of blocks popped up near the middle of the new map, a cluster I’d not noticed before, even though they were clearly somewhat sizable. I moused over to see what they were.
They were CD-R master images.
Images of my daughter’s medical records.
Of her MRIs.
Somewhere in there, her final brain scans, the ones where the doctors did not even bother to count the emerging tumors, there were so many.
There’s enough data in there to recreate 3D models of her brain as it turned on itself. Enough to reconstruct the cartography of her death.
I should just delete it. Keeping the information is pointless now, when it cannot save her, a reminder of futility and helplessness. It’s worse than useless — because if a treatment is one day discovered, the data in these files could torture us with the certainty that her life could have been saved, if only it had started later. Better to not know, and eke out an existence in the spare shelter of ignorance.
I’m not sure I can delete it. No matter how horrifying the images and records might fundamentally be, they feel like pieces of her, tiny bits of her life and death. That erasure of data would feel like an erasure of history. Like a betrayal. Even to shunt them from my primary machine to some sort of backup storage would feel the same as I did when we carefully packed all of her favorite toys and kindergarten drawings into a box, and stored it away, out of sight but never out of perception.
Perhaps I might feel differently if I hadn’t been missing her so keenly the past few weeks. There doesn’t seem to be a specific reason for this, unless it’s the beginning of this specific school year. We’ve all been feeling it, in our own ways. A few days ago, in the middle of a weekend afternoon, the family was at home and just being a family when I suddenly felt her absence like a spiky, sickly, impossible hole in the center of the world. It was as sharp and present as the rush of first love, very nearly tangible and visible.
I look at these files, knowing that there are no rational reasons to keep them and many reasons — rational or otherwise — to let them go. I envision erasing them, and I can’t. All these jagged bits of the past, which do not cling to me; rather, I cling to them, senselessly, hopelessly, afraid to look at them but afraid to let go. Perhaps I believe that with enough of these tiny memories, these shards of her life and death, I can cobble together a wall that will shut out the void her absence tore open.
Just enough to keep functioning, for a little while longer.
Which is, I sometimes think, the worst betrayal of all.
It was right about now, exactly two decades ago, that I pulled on my Tom Servo “I’M HUGE” T-shirt and strolled from my apartment over to Strosacker Auditorium for the CWRU Film Society’s screening of MST3K: The Movie. I’d gotten the evening off from my tech crew duties on Schoolhouse Rock Live! at the Beck Center so that I could catch the movie in a theater again, having been one of the few who’d seen it during its initial theatrical run. To say I was looking forward to it was an understatement. I’d been a fan ever since my high school best friend, Dave, had introduced me to it with a VHS copy of the “Rocketship X-M” episode. The first HTML document I ever marked up was a copy of the MST3K Episode Guide I’d found on Usenet.
I was a staff member of the Film Society, as well as of the university — at that point I was just over a couple of years into being the campus Webmaster and, more or less coincidentally, not quite a couple of years into being divorced. The Film Society was a fun way to pass weekend nights in good company, contribute to a collective effort, and get to see a bunch of movies. So when I pushed through the glass lobby doors, I looked around to see what needed to be done. The ticket counter was already staffed by a couple of people, neither of whom I’d ever seen before. Which was to be expected, a month into the fall semester. We always picked up a few new members as incoming students got adjusted to campus life and looked for stuff to do. I clearly remember one of them, a laughing girl with short-ish curly hair and a unique clothing style.
I remember because later that evening, after I’d seen the movie and was manning the concession stand for one of the later shows, she wandered over to see if I needed any help, then stayed to flirt. For once in my life, I smoothly responded in kind. We kept up the good-natured banter throughout the evening, peppering it with sharp looks and sardonic grins. As things were winding down on the last show, just as I was opening my mouth to ask her if she’d like me to walk her home, she asked me if I’d like to walk her home.
And that’s how Kat and I met, twenty years ago tonight.
Anyone who knew either of us well would never have pegged the other as a likely match. She wasn’t even an MST3K fan: she’d come to Film Society that night, a month into her graduate school studies, to join up and thus have a group to hang out with, and hadn’t even really looked at the schedule first. We had wildly different tastes in music, art, food, recreation, even basic relationship expectations. And yet, somehow, one way or another, with a lot of work and a lot of luck, it’s worked out.
In the time since, we’ve had experiences more amazing and suffered more deeply than either of us could have imagined, as we traded tidbits of information and innuendo over an array of candy bars that balmy September evening. We’ve each shown strength neither of us would have imagined in ourselves. I think we also bring out the best in each other, and that too is a kind of strength.
Two decades. Hard to believe, sometimes, but we did it…and, as Crow might say, I’d do it again if I had to.
The Web is celebrating its 25th anniversary today, taking as its starting point the March 1989 publication of “Information Management: A Proposal”. I was honored to contribute a small greeting to the Greetings page over at The Web At 25. Following on that, I wanted to add a few more words here, mostly about my own Web history, because the Web is nothing if not a vast collection of all of us sharing ourselves.
I was first exposed to the Web in mid- to late 1993 by my friend and (then) co-worker, Jim Nauer, and it instantly caught my imagination. I’d worked on some hypertext systems before, including a summer spent on a DOS-based hypertext system whose name now escapes me that was used to mark up the Ohio Legal Code on CD-ROM for a publisher named Banks-Baldwin, now a division of Thomson Reuters. This Web thing, though, this was something altogether different and more powerful. By late fall I’d gotten my hands on a paper copy of the HTML 2.0 specification and on December 3th, 1993, I finished marking up my first document: the Incomplete Mystery Science Theater 3000 Episode Guide.
At the time, I was a hardware jockey for the Library Information Technologies department at Case Western Reserve University, swapping out bad SIMM chips in online catalog terminals and maintaining a database of equipment serial numbers. So in my downtime between service calls and database updates, I had the freedom to install Mosaic betas and start surfing around to see what there was to be seen. My increasing obsession with the Web eventually led me to become Webmaster of CWRU’s first “pure” Web site. (Before that, there was an HTTP interface to our Gopher server, which was the first www.cwru.edu.) And as part of that, I published tutorials and compatibility charts and spent a lot of time on Usenet and mailing lists dedicated to this new Web thing.
I do remember the moment that the Web blew me away a second time, and it’s a moment of total coincidence, which is of course why I remember it. On April 3rd, 1996, I discovered (I forget exactly how) that CNN had a Web site, and I was astonished — a news network taking the Web seriously? Really? So I loaded it up, and the top headline was “RON BROWN KILLED IN PLANE CRASH” or words to that effect. We turned on a radio, and there was nothing about the crash for at least an hour, maybe more, and of course newspapers wouldn’t have anything to say until morning, and I remember thinking: What is wrong with these other channels, that they’re so slow and unresponsive? That was my first direct glimpse of the future of information velocity, something that permanently altered my instincts.
Over the years, the Web has obviously been good to me, and I’ve tried to be good to it in return. The original Internet aesthetic of sharing what you know and making use of what others share, one that carried onto the early Web, has always resonated with me, as did the obvious simplicity (and thus robustness) of the Web itself. As simple as possible, and no simpler; small pieces loosely joined; openness to all — these are principles I held dear and which the Web has always embodied. Which means that the Web helped me maintain those principles, over these past two decades, by showing that they can and do work.
As I said in my greeting for The Web at 25:
The web is the most human information system we have ever seen and that may ever be, open to anyone with the interest to build something, gargantuan and riotous and everything we are and hope to be. It’s been a privilege just to witness its emergence, let alone play a part in it.
I suppose I could have just posted that here, and skipped the lengthy reminiscing, but what fun would that be?
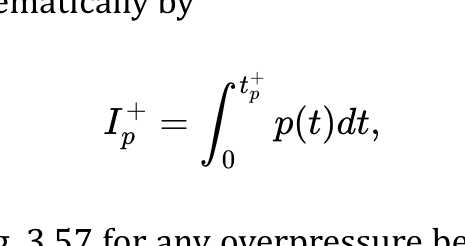




.jpg){kind=link}