As you might have noticed, I recently wrote about how I got started with CSS a quarter century ago, what I’ve seen change over that long span of time, and the role testing has played in both of those things.
After all, CSS tests are most of how I got onto the Cascading Style Sheets & Formatting Properties Working Group (as it was known then) back in the late 1990s. After I’d finished creating tests for nearly all of CSS, I wrote the chair of the CSS&FP WG, Chris Lilley, about it. The conversation went something like, “Hey, I have all these tests I’ve created, would the WG or browser makers be at all interested in using them?” To which the answer was a resounding yes.
Not too much later, I made some pithy-snarky comment on www-style about how only the Cool Kids on the WG knew what was going on with something or other, and I wasn’t one of them, pout pout. At which point Chris emailed me to say something like, “We have this role called Invited Expert; how would you like to be one?” To which the answer was a resounding (if slightly stunned) yes.
I came aboard with a lot of things in mind, but the main thing was to merge my test suite with some other tests and input from smart folks to create the very first official W3C test suite. Of any kind, not just for CSS. It was announced alongside the promotion of CSS2 to Recommendation status in December 1998.
I stayed an Invited Expert for a few years, but around 2003 I withdrew from the group for lack of time and input, and for the last 17-some years, that’s how it’s stayed. Until now, that is: as of yesterday, I’ve rejoined the CSS Working Group, this time as an official Member, one of several representing Igalia. And fittingly, Chris Lilley was the first to welcome me back.
I’m returning to take back up the mantle I carried the first time around: testing CSS. I intend to focus on creating Web Platform Test entries demonstrating new CSS features, clarifying changes to existing specifications, and filling in areas of CSS that are under-tested. Maybe even to draft tests for things the WG is debating, to explore what a given proposal would mean in terms of real-world rendering.
My thanks to Igalia for enabling my return to the CSS WG, as well as supporting my contributions yet to come. And many thanks to the WG for a warm welcome. I have every hope that I’ll be able to once more help CSS grow and improve in my own vaguely unique way.
After my post the other day about how I got started with CSS 25 years ago, I found myself reflecting on just how far CSS itself has come over all those years. We went from a multi-year agony of incompatible layout models to the tipping point of April 2017, when four major Grid implementations shipped in as many weeks, and were very nearly 100% consistent with each other. I expressed delight and astonishment at the time, but it still, to this day, amazes me. Because that’s not what it was like when I started out. At all.
I know it’s still fashionable to complain about how CSS is all janky and weird and unapproachable, but child, the wrinkles of today are a sunny park stroll compared to the jagged icebound cliff we faced at the dawn of CSS. Just a few examples, from waaaaay back in the day:
In the initial CSS implementation by Netscape Navigator 4, padding was sometimes a void. What I mean is, you could give an element a background color, and you could set a border, but if you adding any padding, in some situations it wouldn’t take on the background color, allowing the background of the parent element to show through. Today, we can recreate that effect like so:
But we didn’t havebackground-clip in those days, and backgrounds weren’t supposed to act like that. It was just a bug that got fixed a few versions later. (It was easier to get browsers to fix bugs in those days, because the web was a lot smaller, and so were the stakes.) Until that happened, if you wanted a box with border, background, padding, and content in Navigator, you wrapped a <div> inside another <div>, then applied the border and background to the outer and the padding (or a margin, at that point it didn’t matter) to the inner.
In another early Navigator 4 version, pica math was inverted: Instead of 12 points per pica, it was set to 12 picas per point — so 12pt equated to 144pc instead of 1pc. Oops.
Navigator 4’s handling of color values was another fun bit of bizarreness. It would try to parse any string as if it were hexadecimal, but it did so in this weird way that meant if you declared color: inherit it would render in, as one person put it, “monkey-vomit green”.
Internet Explorer for Windows started out by only tiling background images down and to the right. Which was fine if you left the origin image in the top left corner, but as soon as you moved it with background-position, the top and left sides of the element just… wouldn’t have any background. Sort of like Navigator’s padding void!
At one point, IE/Win (as we called it then) just flat out refused to implement background-position: fixed. I asked someone on that team point blank if they’d ever do it, and got just laughter and then, “Ah no.” (Eventually they relented, opening the door for me to create complexspiral and complexspiral distorted.)
For that matter, IE/Win didn’t inherit font sizes into tables. Which would be annoying even today, but in the era of still needing tables to do page-level layout, it was a real problem.
IE/Win had so many layout bugs, there were whole sites dedicated to cataloging and explaining them. Some readers will remember, and probably shudder to do so, the Three-Pixel Text Jog, the Phantom Box Bug, the Peekaboo Bug, and more. Or, for that matter, hasLayout/zoom.
And perhaps most famous of all, Netscape and Opera implemented the W3C box model (2021 equivalent: box-sizing: content-box) while Microsoft implemented an alternative model (2021 equivalent: box-sizing: border-box), which meant apparently simple CSS meant to size elements would yield different results in different browsers. Possibly vastly different, depending on the size of the padding and so on. Which model is more sensible or intuitive doesn’t actually matter here: the inconsistency literally threatened the survival of CSS itself. Neither side was willing to change to match the other — “we have customers!” was the cry — and nobody could agree on a set of new properties to replace height and width. It took the invention of DOCTYPE switching to rescue CSS from the deadlock, which in turn helped set the stage for layout-behavior properties like box-sizing.
I could go on. I didn’t even touch on Opera’s bugs, for example. There was just so much that was wrong. Enough so that in a fantastic bit of code aikido, Tantek turned browsers’ parsing bugs against them, redirecting those failures into ways to conditionally deliver specific CSS rules to the browsers that needed them. A non-JS, non-DOCTYPE form of browser sniffing, if you like — one of the earliest progenitors of feature queries.
I said DOCTYPE switching saved CSS, and that’s true, but it’s not the whole truth. So did the Web Standards Project, WaSP for short. A group of volunteers, sick of the chaotic landscape of browser incompatibilities (some intentional) and the extra time and cost of dealing with them, who made the case to developers, browser makers, and the tech press that there was a better way, one where browsers were compatible on the basics like W3C specifications, and could compete on other features. It was a long, wearying, sometimes frustrating, often derided campaign, but it worked.
The state of the web today, with its vast capability and wide compatibility, owes a great deal to the WaSP and its allies within browser teams. I remember the time that someone working on a browser — I won’t say which one, or who it was — called me to discuss the way the WaSP was treating their browser. “I want you to be tougher on us,” they said, surprising the hell out of me. “If we can point to outside groups taking us to task for falling short, we can make the case internally to get more resources.” That was when I fully grasped that corporations aren’t monoliths, and formulated my version of Hanlon’s Razor: “Never ascribe to malice that which is adequately explained by resource constraints.”
The original Acid Test.
In order to back up what we said when we took browsers to task, we needed test cases. This not only gave the CSS1 Test Suite a place of importance, but also the tests the WaSP’s CSS Action Committee (aka the CSS Samurai) devised. The most famous of these is the first CSS Acid Test, which was added to the CSS1 Test Suite and was even used as an Easter egg in Internet Explorer 5 for Macintosh.
The need for testing, whether acid or basic, lives on in the Web Platform Tests, or WPT for short. These tests form a vital link in the development of the web. They allow specification authors to create reference results for the rules in those specifications, and they allow browser makers to see if the code they’re writing yields the correct results. Sometimes, an implementation fails a test and the implementor can’t figure out why, which leads to a discussion with the authors of the specification, and that can lead to clarifications of the specification, or to fixing flawed tests, or even to both. Realize just how harmonious browser support for HTML and CSS is these days, and know that WPT deserves a big part of the credit for that harmony.
As much as the Web Standards Project set us on the right path, the Web Platform Tests keep us on that path. And I can’t lie, I feel like the WPT is to the CSS1 Test Suite much like feature queries are to those old CSS parser hacks. The latter are much greater and more powerful than than the former, but there’s an evolutionary line that connects them. Forerunners and inheritors. Ancestors and descendants.
It’s been a real privilege to be present as CSS first emerged, to watch as it’s developed into the powerhouse it is today, and to be a part of that story — a story that is, I believe, far from over. There are still many ways for CSS to develop, and still so many things we have yet to discover in its feature set. It’s still an entrancing language, and I hope I get to be entranced for another 25 years.
It was the morning of Tuesday, May 7th and I was sitting in the Ambroisie conference room of the CNIT in Paris, France having my mind repeatedly blown by an up-and-coming web technology called “Cascading Style Sheets”, 25 years ago this month.
I’d been the Webmaster at Case Western Reserve University for just over two years at that point, and although I was aware of table-driven layout, I’d resisted using it for the main campus site. All those table tags just felt… wrong. Icky. And yet, I could readily see how not using tables hampered my layout options. I’d been holding out for something better, but increasingly unsure how much longer I could wait.
Having successfully talked the university into paying my way to Paris to attend WWW5, partly by having a paper accepted for presentation, I was now sitting in the W3C track of the conference, seeing examples of CSS working in a browser, and it just felt… right. When I saw a single word turned a rich blue and 100-point size with just a single element and a few simple rules, I was utterly hooked. I still remember the buzzing tingle of excitement that encircled my head as I felt like I was seeing a real shift in the web’s power, a major leap forward, and exactly what I’d been holding out for.
Page 4, HTML 3.2.
Looking back at my hand-written notes (laptops were heavy, bulky, battery-poor, and expensive in those days, so I didn’t bother taking one with me) from the conference, which I still have, I find a lot that interests me. HTTP 1.1 and HTML 3.2 were announced, or at least explained in detail, at that conference. I took several notes on the brand-new <OBJECT> element and wrote “CENTER is in!”, which I think was an expression of excitement. Ah, to be so young and foolish again.
There are other tidbits: a claim that “standards will trail innovation” — something that I feel has really only happened in the past decade or so — and that “Math has moved to ActiveMath”, the latter of which is a term I freely admit I not only forgot, but still can’t recall in any way whatsoever.
My first impressions of CSS, split for no clear reason across two pages.
But I did record that CSS had about 35 properties, and that you could associate it with markup using <LINK REL=STYLESHEET>, <STYLE>…</STYLE>, or <H1 STYLE="…">. There’s a question — “Gradient backgrounds?” — that I can’t remember any longer if it was a note to myself to check later, or something that was floated as a possibility during the talk. I did take notes on image backgrounds, text spacing, indents (which I managed to misspell), and more.
What I didn’t know at the time was that CSS was still largely vaporware. Implementations were coming, sure, but the demos I’d seen were very narrowly chosen and browser support was minimal at best, not to mention wildly inconsistent. I didn’t discover any of this until I got back home and started experimenting with the language. With a printed copy of the CSS1 specification next to me, I kept trying things that seemed like they should work, and they didn’t. It didn’t matter if I was using the market-dominating behemoth that was Netscape Navigator or the scrappy, fringe-niche new kid Internet Explorer: very little seemed to line up with the specification, and almost nothing worked consistently across the browsers.
So I started creating little test pages, tackling a single property on each page with one test per value (or value type), each just a simple assertion of what should be rendered along with a copy of the CSS used on the page. Over time, my completionist streak drove me to expand this smattering of tests to cover everything in CSS1, and the perfectionist in me put in the effort to make it easy to navigate. That way, when a new browser version came out, I could run it through the whole suite of tests and see what had changed and make note of it.
Eventually, those tests became the CSS1 Test Suite, and the way it looks today is pretty much how I built it. Some tests were expanded, revised, and added, plus it eventually all got poured into a basic test harness that I think someone else wrote, but most of the tests — and the overall visual design — were my work, color-blindness insensitivity and all. Those tests are basically what got me into the Working Group as an Invited Expert, way back in the day.
Before that happened, though, with all those tests in hand, I was able to compile CSS browser support information into a big color-coded table, which I published on the CWRU web site (remember, I was Webmaster) and made freely available to all. The support data was stored in a large FileMaker Pro database, with custom dropdown fields to enter the Y/N/P/B values and lots of fields for me to enter template fragments so that I could export to HTML. That support chart eventually migrated to the late Web Review, where it came to be known as “the Mastergrid”, a term I find funny in retrospect because grid layout was still two decades in the future, and anyway, it was just a large and heavily styled data table. Because I wasn’t against tables for tabular data. I just didn’t like the idea of using them solely for layout purposes.
And it all kicked off 25 years ago this month in a conference room in Paris, May 7th, 1996. What a journey it’s been. I wonder now, in the latter half of my life, what CSS — what the web itself — will look like in another 25 years.
For my 2020 holiday break, I decided to get more serious about supporting the use of alternative text on Twitter. I try to be rigorous about adding descriptive text to my images, GIFs, and videos, but I want to be more conscientious about not spreading inaccessible content through my retweets.
The thing is, Twitter doesn’t make it obvious whether someone else’s content has been described, and the way it structures (if I can reasonably use that word) its content makes it annoyingly difficult to conduct element or accessibility-property inspections. So, in keeping with the design principles that underlie both the Web and CSS, I decided to take matters into my own hands. Which is to say, I wrote a user stylesheet.
I started out by calling out things that lacked useful alt text. It went something like this:
…and so on, layering on some sizing, font stuff, and positioning to hopefully place the text where it would be visible. This failed to satisfy for two reasons:
Because of the way Twitter nests it dozens of repeatedly utility-classes divs, and the styles repeatedly applied thereby, many images were tall (but cut off) or wide (ditto) in ways that pulled the positioned generated text out of the visible frame shown on the site. There wasn’t an easily-found human-readable predictable way to address the element I wanted to use as a positioning context. So that was a problem.
Almost every image in my feed had a big red and yellow WARNING on it, which quickly depressed me.
What I realized was that rather than calling out the failures, I needed to highlight the successes. So I commented out the Big Red Angry Text approach above and got a lot more simple.
Three consecutive tweets from my timeline on Friday, January 1st, 2021. The blurring of the images in the top and bottom tweets is an effect of the Data Saver preference, not my CSS.
Just that. De-emphasize the images that have the default alt text by way of their enclosing divs, and remove that effect on hover so I can see the image as intended if I so choose. I like this approach better because it de-emphasizes images that aren’t properly described, while those which are described get a visual pop. They stand out as lush islands in a flat sea.
In case you’ve been wondering why I’m selecting divs instead of img and video elements, it’s because I use the Data Saver setting on Twitter, which requires me to click on an image or video to load it. (You can set it via Settings > Accessibility, display and languages > Data usage > Data saver. It’s also what’s blurring the images in the screenshot shown here.) I enable this setting to reduce network load, but also to give me an extra layer of protection when disturbing images and videos circulate. I generally follow people who are careful about not sharing disturbing content, but I sometimes go wandering outside my main timeline, and never know what I’ll find out there.
After some source digging, I discovered a decent way to select non-described videos, which I combined with the existing image styles:
The fun part is, Twitter’s architecture spits out nested divs with that same ARIA label for videos, which I imagine could be annoying to people using screen readers. Besides that, it also has the effect of applying the filter twice, which means videos that haven’t been described get their contrast double-reduced! And their grayscale double-enforced! Fun.
What I didn’t expect was that when I start playing a video, it loses the grayscale and contrast reduction effects even when not being hovered, which makes the second rule above a little over-written. I don’t see the DOM structure changing a whole lot when the video loads and plays, so either videos are being treated differently for filter purposes, or I’m missing something in the DOM that’s invalidating the selector matching. I might poke at it over time to find a fix, or I may just let it go. The user experience isn’t too far off what I wanted anyway.
There is a gap in my coverage, which is GIFs pulled from Twitter’s GIF pool. These have default alt text other than Image, which makes selecting for them next to impossible. Just a few examples pulled from Firefox’s Accessibility panel when I searched the GIF panel for “this is a test”:
testing GIF
This Is ATest Fool GIF
Corona Test GIF by euronews
Test Fail GIF
Corona Virus GIF by guardian
Its ATest Josh Subdquist GIF
Corona Stay Home GIF by INTO ACTION
Is This A Test GIF
Stressed Out Community GIF
A1b2c3 GIF
I assume these are Giphy titles or something like that. In nearly every case, they’re insufficient, if not misleading or outright useless. I looked for markers in the DOM to be able to catch these, but didn’t find anything that was obviously useful.
I did think briefly about filtering for any aria-label that contains the string GIF ([aria-label*="GIF"]), but that would improperly catch images and videos that have been described but happen to have the string GIF inside them somewhere. This might be a relatively rare occurrence, but I’m loth to gray out media that someone went to the effort of describing. I may change my mind about this, but for now, I’m accepting that GIFs which appear in full color are probably not described, particularly when containing common memes, and will try to be careful.
I apply the above styles in Firefox using Stylus, which also available for Chrome, and they’re working pretty well for me. I wish I could figure out a way to apply them in mobile contexts, but that’s a (much bigger) problem for another day.
I’m not the first to tread this ground, nor do I expect to be the last, sadly. For a deeper dive into all the details of Twitter accessibility and the pitfalls that can occur, please read Adrian Roselli’s excellent article Improving Your Tweet Accessibility from just over two years ago. And if you want apply accessibility-aid CSS to your own Twitter experience but can’t or won’t use Stylus, Adrian has a bookmarklet that injects Twitter alt text all set up and ready to go — you can use it as-is, or replace the CSS in his bookmarklet with mine above or your own if you want to take a different approach.
So that’s how I’m upping my awareness of accessible content on Twitter in 2021. I’d love to hear what y’all are using to improve your own experiences, or links to tools and resources on this same topic. If you have any of that, please drop the links in a comment below, so that everyone who reads this can benefit. Thanks!
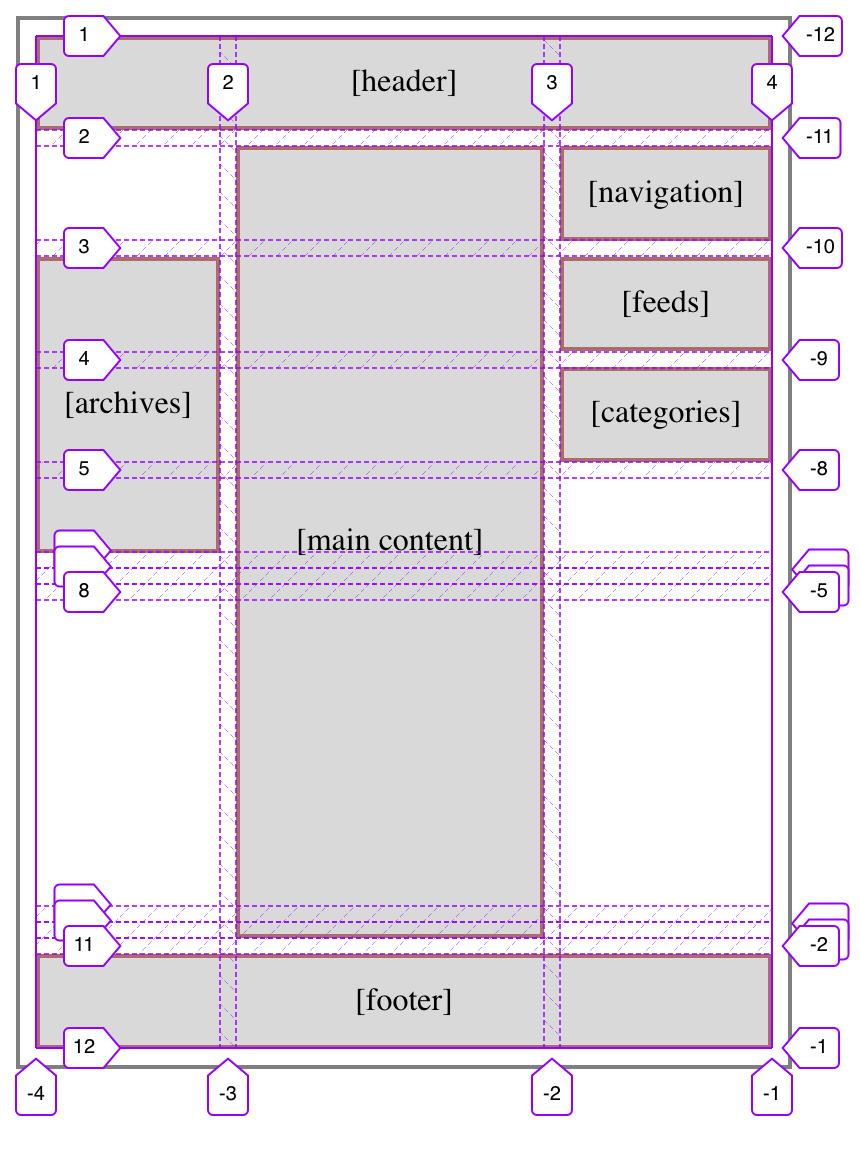
Another aspect of the meyerweb redesign I’d like to explore is the way I’m using CSS Grid rows to give myself more layout flexibility.
First, let’s visualize the default layout of a page here on meyerweb. It looks something like this:
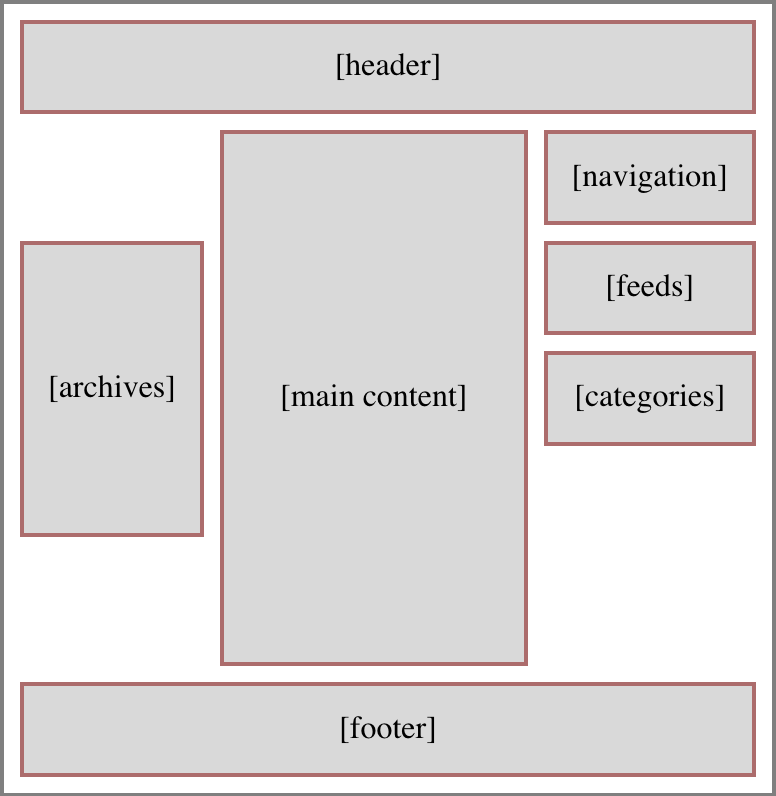
So simple, even flexbox could do it! But that’s only if things always stay this simple. I knew they probably wouldn’t, because the contents in those two sidebars were likely to vary from one part of the site to another — and I would want, in some cases, for the sidebar pieces to line up vertically. Here’s an example:
That’s the basic layout of archive pages. See how the left sidebar’s Archives lines up with the top of the Feeds box in the right sidebar? That’s Grid for you. I thought about lumping the Feeds and Categories into a the same grid cell (thus making them part of the same grid row), which would have meant wrapping them in a <div>, but decided keeping them separate allows more flexibility in terms of responsive rearrangement of content. I can, for example, assign the Feeds to be followed by Archives and then Categories at mobile sizes. Or to reverse that order.
More to the point, I also wanted the ability to place things along the bottoms of the sidebars, down near the footer but still next to the main content column, like so:
An early design prototype for the blog archives put the “Next post” and “Previous post” links in some of those spots, before I moved the links into the bottom of the main content column. So at the moment, I don’t have anything making use of those spots, although the capability is there. I could cluster content along the tops and the bottoms of the sidebars, as needed.
But here’s the important thing, and really the point of this article: I’m not rewriting the row structure and grid cell assignments for each page type. There’s a unified row template applied to the body on every page that uses the Hamonshū design. It is:
The general idea here is, the first seven rows are sized to be the minimum necessary to contain content inside those rows. This is also true of the last three rows. And in between those sets, a 1fr row that takes up the rest of the grid container’s height, pushing the two sets apart.
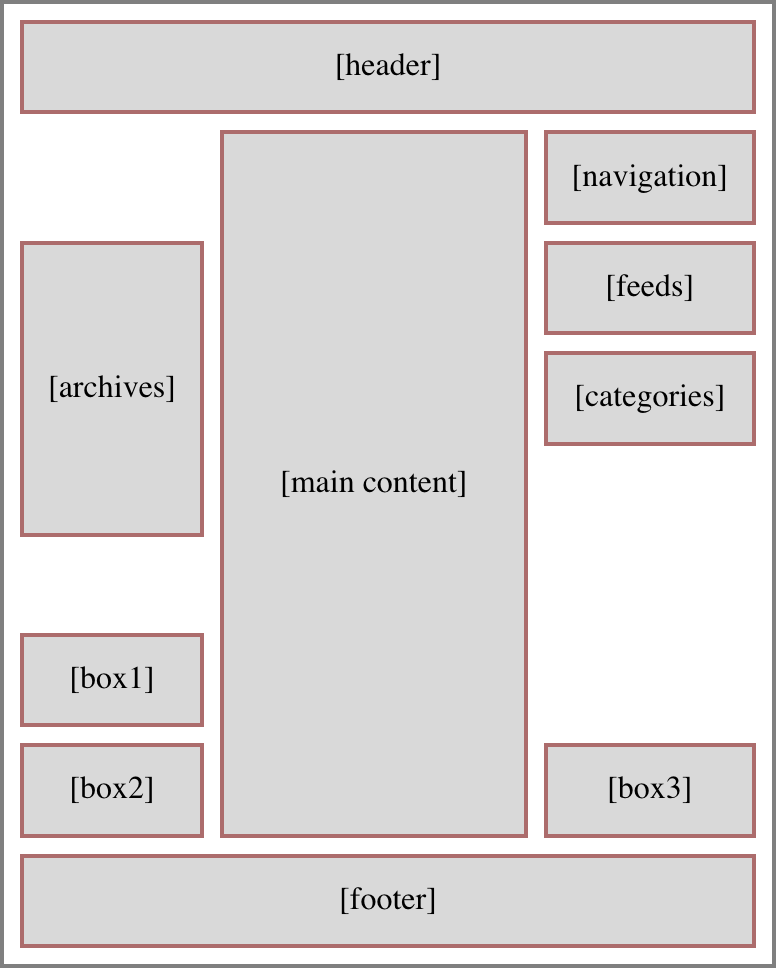
In the simplest case, where there’s just a header, main content column, and a footer, with nothing in the sidebars (the layout has three columns, remember), the content will fill the rows like so:
Thus: The header fills all of row one. The content expands row two from its placement in the center column. The footer fills all of the last row, which is specified via grid-row: -2 (because grid-row: -1 would align its top with the bottom edge of the grid container). There’s no more content, so all the other min-content rows have no content, so their height is zero. And there’s no leftover height to soak up, so the 1fr row also has a height of zero. Seems like a lot of rows specified to no real purpose, doesn’t it?
But now, let’s add some sidebar content to columns one and three; that is, the sidebars. For example, you might remember this layout from before:
Given this setup, we can’t just assign the main content column to grid-row: 2 and leave it at that — it’s going to have to span rows. Really, it needs to span all but the last, thus ensuring it reaches down to the footer. So the CSS ends up like this:
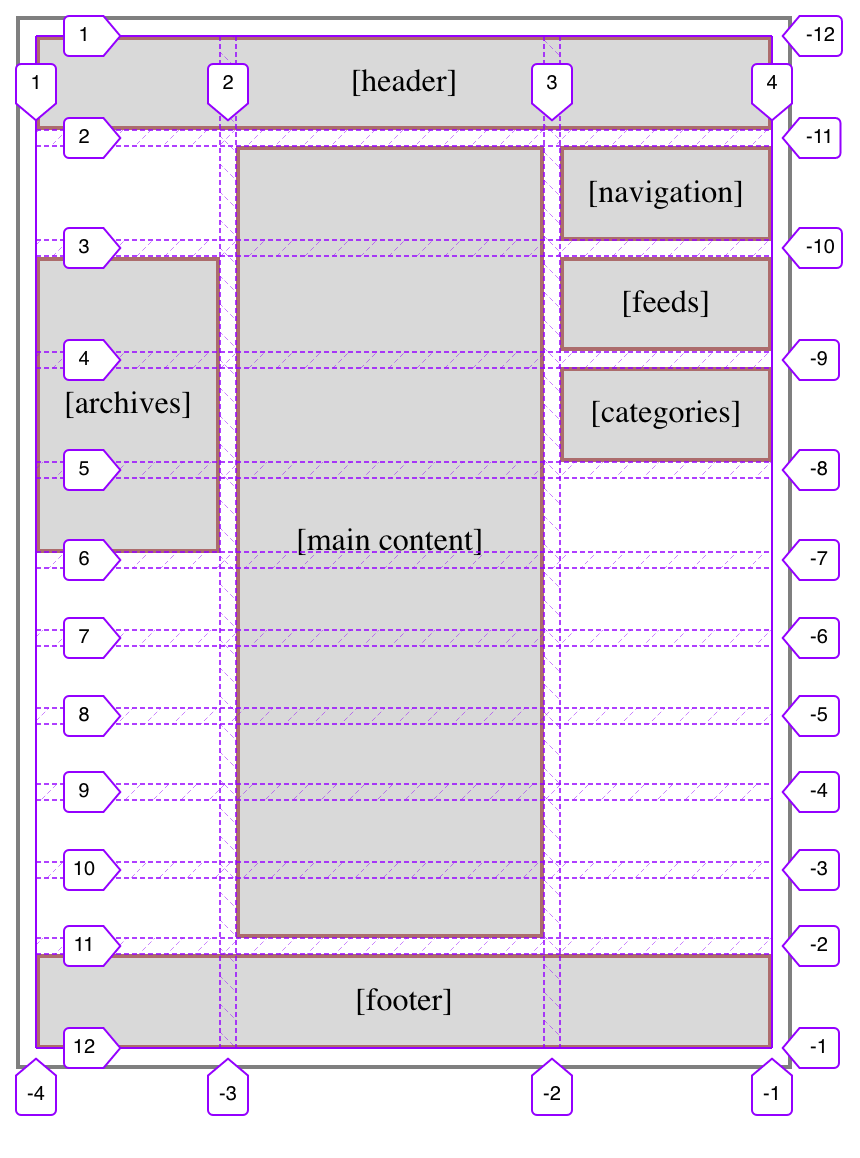
Grid-line visualization courtesy the Firefox Web Inspector.
The first set of min-content rows are all gathered up against the bottom of the top part of the layout, and the second set are all pushed down at the bottom. Between them, the 1fr row eats up all the leftover space, which is what pushes the two sets of min-content rows apart.
I like this pattern. It feels good to me, having two sets of rows where the individual rows accordion open to accept content when needed, and collapse to zero height when not, with a “blank” row in between the sets that pushes them apart. It’s flexible, and even allows me to add more rows to the sets without having to rewrite all my layout styles.
As an example, suppose I decided I needed to add a few more rows to the bottom set, for use in a few specialty templates. Because of the way things are set up, all I have to do is change the row template like this:
That’s everything. I just changed the number of repeats in the second set of rows. All the existing pages will continue on just fine, no layout changes, no CSS changes. In the few (currently hypothetical) pages where I need to put a bunch of stuff along the bottom of the main content column, I just plug them in using grid-row values, whether positive or negative. It all just works.
The same is true if more rows are added to the first set, for whatever reason. Everything gets managed in a single CSS rule, where you can add rows for the whole site instead of having to write, track, and maintain a bunch of variants for various page types. (Subtracting rows is harder without causing layout upset, but could still be done in some scenarios.)
As a final note, you’re probably wondering: Is that one 1fr row actually necessary to get a layout like this one? Not really, no. Let’s take it out, like this:
grid-template-rows: repeat(11,min-content);
What happens as a result is the rows that aren’t directly occupied by content (the ones that previously collapsed to zero height), but are still spanned by content (the center column), divvy up the leftover space the 1fr row used to consume. This leads to a situation like so:
To the user, there’s no practical difference. Things go to the same places either way. You just get the “extra” rows stretching out, instead of being pushed apart by the 1fr row.
I certainly could have left it at that, and it arguably would have been cleaner to do so. But something about this approach doesn’t sit quite right with me; there’s a tickly feeling in the back of my instinct that tells me there’s a downside to this. Admittedly, it could be a vestigial instinct from the Age of Floats; I doubtless have many things I still have not unlearned. On the other hand, it could be something about Grid I’ve picked up on subconsciously but haven’t yet brought into full realization.
If I ever pin the tickle down enough to articulate it, I’ll update the post to include it.
I’ve been incredibly gratified and a bit humbled by the responses to the new design. So first of all, thank you to everyone who shared their reactions! I truly appreciate your kindness, and I’d like to repay that kindness a bit by sharing some of the techniques I used to create this design. Today, let’s talk about the ink-study illustrations placed between entries on the site, as well as one other place I’ll get to later.
Very early in the process, I knew I wanted to separate entries with decorations of some sort, as a way of breaking up the stream of text. Fortunately, Hamonshū provided ample material. A little work in Acorn and I had five candidate illustrations ready to go.
The five illustrations.
The thing was, I wanted to use all five of them, and I wanted them to be picked on a random-ish basis. I could have written PHP or JS or some such to inject a random pick, but that felt a little too fiddly. Fortunately, I found a way to use plain old CSS to get the result I wanted, even if it isn’t truly random. In fact, its predictability became an asset to me as a designer, while still imparting the effect I wanted for readers.
(Please note that in this article, I’ve simplified some aspects of my actual CSS for clarity’s sake; e.g., removing the directory path from url() values and just showing the filenames, or removing declarations not directly relevant to the discussion here. I mention this so that you’re prepared for the differences in the CSS shown in this piece versus in your web inspector and/or the raw stylesheet.)
That means, for every blog entry except the first, a block-level bit of generated content is inserted at the beginning of the entry, given a height, and the image separator-big-05.png is dropped into the generated box and sized to be contained within it, which means no part of the image will spill outside the background area and thus be clipped off. (The file has the number 05 because it was the fifth I produced. It ended up being my favorite, so I made it the default.)
With that in place, all that remains is to switch up the background image that’s used for various entries. I do it like this:
So every second-plus-one entry (the third, fifth, seventh, etc.) that isn’t the first entry will use separator-big-02.png instead of -05.png. Unless the entry is an every-third-plus-one (fourth, seventh, tenth, etc.), in which case separator-big-03.png is used instead. And so on, up through every-fifth-plus-one. And as you can see, the first image I produced (separator-big-01.png) is used the least often, so you can probably guess where it stands in my regard.
This technique does produce a predictable pattern, but one that’s unlikely to seem too repetitious, because it’s used to add decoration separated by a fair amount of text content, plus there are enough alternatives to keep the mix feeling fresh. It also means, given how the technique works, that the first separator image on the home page (and on archive pages) is always my favorite. That’s where the predictability of the approach helped me as a designer.
I use a similar approach for the separator between posts’ text and their comments, except in that case, I add a generated box to the end of the last child element in a given entry:
That is, on any page classed single (which is all individual post pages) after the last child element of a .text element (which holds the text of a post), the decoration box is generated. The default, again, is separator-big-05.png — but here, I vary the image based on the number of elements in the post’s body:
In other words: if the last child element of the post text is a second-plus-one, separator-big-02.png is used. If there are 3n+1 (one, four, seven, ten, thirteen, …) HTML elements in the post, separator-big-03.png is used. And so on. This is an effectively random choice from among the five images, since I don’t count the elements in my posts as I write them. And it also means that if I edit a piece enough to change the number of elements, the illustration will change! (To be clear, I regard this as a feature. It lends a slight patina of impermanence that fits well with the overall theme.)
I should note that in the actual CSS, the two sets of rules above are merged into one, so the selectors are actually like so:
In all honesty, this technique really satisfies me. It makes use of document structure while having a random feel, and is easily updated by simply replacing files or changing URLs. It’s also simple to add more rules to bring even more images to the mix, if I want.
And since we’re talking about using structure to vary layout, I also have this @media block, quoted here verbatim and in full:
This means on the home page and blog archive pages, but only at desktop-browser widths, some entries are shifted a bit to the left or right by fractions of the viewport width, which subtly breaks up the strict linearity of the content column on long pages, keeping it from feeling too grid-like.
To be honest, I have no idea if that side-shifting effect actually affects visitors’ experience of using meyerweb, but I like it. Sometimes the inter-entry wave art fits together with the side-shift so that it looks like the art flows into the content. That kind of serendipity always delights me, whether it comes by my hand or someone else’s. With luck, it will have delighted one or two of you as well.
If you’re here on meyerweb on April 9th, 2020, then you’re seeing the site without the CSS I wrote for its design and layout. Why? It’s CSS Naked Day! To quote that site:
The idea behind this event is to promote Web Standards. Plain and simple. This includes proper use of HTML, semantic markup, a good hierarchy structure, and of course, a good old play on words. It’s time to show off your <body> for what it really is.
So last night, I removed the links to the main stylesheets for the site. There are, I should note, scattered pages where local CSS is still in play. I could have tracked them all down and removed their CSS as well, and I considered doing so, but in the end I decided against it.
There’s a history to this day. In the late Aughts, it was an annual thing, not unlike Blue Beanie Day, to draw attention to web standards and reinforce among the community that good, solid, robust development practices are a good thing. Because after all, if your site isn’t usable without the CSS, then it almost certainly has structure and accessibility problems you probably haven’t been thinking about.
In all honesty, I had forgotten about it until just a couple of days prior, I suddenly thought, “Wait, early April, isn’t that when CSS Naked Day was observed?” I went looking, and discovered that yes, it was. I had remembered April 7th, but apparently April 9th was the actual date. Or became it over time. Either way, here we are, feeling fancy-free!
What’s been interesting has been what CSS Naked Day has revealed about browsers as well as about our HTML. To pick one example, suppose you have a very large SVG logo, which you size to where you want it with CSS. This is ordinarily a best practice: the SVG is the same file size whether it renders huge or tiny, so there’s no downside to having an SVG that renders 1200 x 1000 when you view it directly — thus allowing you to see all the little details — but is sized to 120 x 100 via CSS for layout purposes.
But take away the CSS, and the SVG will become 1200 x 1000 again. That might tell you to resize it for production, sure, and you probably should. But it also points out that browsers will not constrain that image, not even to the viewport. If your window is only 900 pixels wide, the SVG could well spill outside, forcing a horizontal scrollbar. Is that good? Maybe! Maybe not! We might wish browsers would bake something like img {max-width: 100%; height: auto;} into their user-agent stylesheet(s), but maybe that would have unforeseen downsides. The point is, this is a thing about browsers that CSS Naked Day reveals, and it’s worth knowing.
Similarly, this reveals that browsers don’t have a way to restrict the width of lines of text. Thus, if the browser window is wide, the lines get very long — long enough to make reading more difficult. This isn’t a problem on handheld devices like smartphones, but on desktop (use of which has risen significantly in areas locked down to limit the spread of SARS-CoV-2) it can be a problem. Again, if browsers had something like body {max-width: 70em;} or max-width: 100ch or suchlike, this wouldn’t be a problem. Should they? Maybe! It’s worth thinking about for your own work, if nothing else.
(For much more thinking about these kinds of browser behaviors and how to address them, you should absolutely check out the CSS Remedy project. “CSS Remedy sets CSS properties or values to what they would be if the CSSWG were creating the CSS today, from scratch, and didn’t have to worry about backwards compatibility.”)
If I’d remembered sooner, I might have contacted the maintainers of the CSS Naked Day site and posted about it ahead of time and thought about stuff like a hashtag to spread the word. Maybe that will happen next year. Until then, enjoy all the nudity!
Back in 2011, I decided to make a timeline out of CSS modules’ version histories, where “version history” means “a list of all the various drafts that were published”. I updated the data every now and again, and then kind of let it go dormant for a few years.
Until this past weekend, when for no clear reason I decided what the hell, it’s time for a refresh. So I trawled through all the specs’ version histories to get the stuff I didn’t have, and gave the presentation a bit of an upgrade. The overall look and feel is pretty consistent, except now, thanks to repeating linear gradients, I have vertical stripes to show each year in the now 21-year-long timeline. I put labels up at the top of the stripes, and figured they should remain visible no matter where you scroll, so I set them to position: sticky. Then I realized most people would have to scroll horizontally, so I made the specification names sticky as well.
So now, no matter where you scroll on the page, you’ll see the specifications along the left and the years along the top. The layout isn’t mobile-hostile, exactly, but it isn’t RWD-ized either. I’m not really sure how I could make this fully responsive, except maybe to just drop the timeline layout altogether and revert to the lists that underlie the layout.
While I was at it, I converted a fair bit of the CSS to use var() and calc() so that I could set a column width in one place, and sprinkled in just a tiny bit more PHP to output offset values in a couple of places. Nothing major, just quality-of-life upgrades for the maintainer, which is to say, me.
So I’ve added them to the timeline, along with CSS Color Module Level 4, which I’d overlooked in my weekend update. These are the first module versions of 2020, so enjoy!
I do find it a little weird that Color Level 5 is out when Color Level 4 has never left Working Draft status, but maybe Level 4 is about to graduate, and this just happened to come out first. We’ll see!