I’ve long made it clear that I don’t particularly care for the whole Shadow DOM thing. I believe I understand the problems it tries to solve, and I fully acknowledge that those are problems worth solving. There are just a bunch of things about it that don’t feel right to me, like how it can break accessibility in a number of ways.
One of those things is how it breaks stuff like the commandFor attribute on <button>s, or the popoverTarget attribute, or a variety of ARIA attributes such as aria-labelledby. This happens because a Shadow DOMmed component creates a whole separate node tree, which creates a barrier (for a lot of things, to be clear; this is just one class of them).
At least, that’s been the case. There’s now a proposal to fix that, and prototype implementations in both Chrome and Safari! In Chrome, it’s covered by the Experimental Web Platform features flag in chrome://flags. In Safari, you open the Develop > Feature Flags… dialog, search for “referenceTarget”, and enable both flags.
(Disclosure: My employer, Igalia, with support from NLnet, did the WebKit implementation, and also a Gecko implementation that’s being reviewed as I write this.)
If you’re familiar with Shadow DOMming, you know that there are attributes for the <template> element like shadowRootClonable that set how the Shadow DOM for that particular component can be used. The proposal at hand is for a shadowRootReferenceTarget attribute, which is a string used to identify an element within the Shadowed DOM tree that should be the actual target of any references. This is backed by a ShadowRoot.referenceTarget API feature.
Take this simple setup as a quick example.
<label for="consent">I agree to join your marketing email list for some reason</label>
<sp-checkbox id="consent">
<template>
<input id="setting" type="checkbox" aria-checked="indeterminate">
<span id="box"></span>
</template> </sp-checkbox>
Assume there’s some JavaScript to make that stuff inside the Shadow DOM work as intended. (No, nothing this simple should really be a web component, but let’s assume that someone has created a whole multi-faceted component system for handling rich user interactions or whatever, and someone else has to use it for job-related reasons, and this is one small use of that system.)
The problem is, the <label> element’s for is pointing at consent, which is the ID of the component. The actual thing that should be targeted is the <input> element with the ID of setting . We can’t just change the markup to <label for="setting"> because that <input> is trapped in the Shadow tree, where none in the Light beyond may call for it. So it just plain old doesn’t work.
Under the Reference Target proposal, one way to fix this would look something like this in HTML:
<label for="consent">I agree to join your marketing email list for some reason</label>
<sp-checkbox id="consent">
<template shadowRootReferenceTarget="setting">
<input id="setting" type="checkbox" aria-checked="indeterminate">
<span id="box"></span>
</template> </sp-checkbox>
With this markup in place, if someone clicks/taps/otherwise activates the label, it points to the ID consent . That Shadowed component takes that reference and redirects it to an effective target — the reference target identified in its shadowRootReferenceTarget attribute.
You could also set up the reference with JavaScript instead of an HTML template:
<label for="consent">I agree to join your marketing email list for some reason</label>
<sp-checkbox id="consent"></sp-checkbox>
class SpecialCheckbox extends HTMLElement {
checked = "mixed";
constructor() {
super();
this.shadowRoot_ = this.attachShadow({
referenceTarget: "setting"
});
// lines of code to Make It Go
}
}
Either way, the effective target is the <input> with the ID of setting .
This can be used in any situation where one element targets another, not just with for . The form and list attributes on inputs would benefit from this. So, too, would the relatively new popoverTargetand commandFor button attributes. And all of the ARIA targeting attributes, like aria-controls and aria-errormessage and aria-owns as well.
If reference targets are something you think would be useful in your own work, please give it a try in Chrome or Safari or both, to see if your use cases are being met. If not, you can leave feedback on issue 1120 to share any problems you run into. If we’re going to have a Shadow DOM, the least we can do is make it as accessible and useful as possible.
For a while now, Web Components (which I’m not going to capitalize again, you’re welcome) have been one of those things that pop up in the general web conversation, seem intriguing, and then fade into the background again.
I freely admit a lot of this experience is due to me, who is not all that thrilled with the Shadow DOM in general and all the shenanigans required to cross from the Light Side to the Dark Side in particular. I like the Light DOM. It’s designed to work together pretty well. This whole high-fantasy-flavored Shadowlands of the DOM thing just doesn’t sit right with me.
If they do for you, that’s great! Rock on with your bad self. I say all this mostly to set the stage for why I only recently had a breakthrough using web components, and now I quite like them. But not the shadow kind. I’m talking about Fully Light-DOM Components here.
It started with a one-two punch: first, I read Jim Nielsen’s “Using Web Components on My Icon Galleries Websites”, which I didn’t really get the first few times I read it, but I could tell there was something new (to me) there. Very shortly thereafter, I saw Dave Rupert’s <fit-vids> CodePen, and that’s when the Light DOM Bulb went off in my head. You just take some normal HTML markup, wrap it with a custom element, and then write some JS to add capabilities which you can then style with regular CSS! Everything’s of the Light Side of the Web. No need to pierce the Vale of Shadows or whatever.
Kindly permit me to illustrate at great length and in some depth, using a thing I created while developing a tool for internal use at Igalia as the basis. Suppose you have some range inputs, just some happy little slider controls on your page, ready to change some values, like this:
The idea here is that you use the slider to change the font size of an element of some kind. Using HTML’s built-in attributes for range inputs, I set a minimum, maximum, and initial value, the step size permitted for value changes, and an ID so a <label> can be associated with it. Dirt-standard HTML stuff, in other words. Given that this markup exists in the page, then, it needs to be hooked up to the thing it’s supposed to change.
In Ye Olden Days, you’d need to write a function to go through the entire DOM looking for these controls (maybe you’d add a specific class to the ones you need to find), figure out how to associate them with the element they’re supposed to affect (a title, in this case), add listeners, and so on. It might go something like:
let sliders = document.querySelectorAll('input[id]');
for (i = 0; i < sliders.length; i++) {
let slider = sliders[i];
// …add event listeners
// …target element to control
// …set behaviors, maybe call external functions
// …etc., etc., etc.
}
Then you’d have to stuff all that into a window.onload observer or otherwise defer the script until the document is finished loading.
To be clear, you can absolutely still do it that way. Sometimes, it’s even the most sensible choice! But fully-light-DOM components can make a lot of this easier, more reusable, and robust. We can add some custom elements to the page and use those as a foundation for scripting advanced behavior.
Now, if you’re like me (and I know I am), you might think of converting everything into a completely bespoke element and then forcing all the things you want to do with it into its attributes, like this:
<super-slider type="range" min="0.5" max="4" step="0.1" value="2"
unit="em" target=".preview h1">
Title font size
</super-slider>
Don’t do this. If you do, then you end up having to reconstruct the HTML you want to exist out of the data you stuck on the custom element. As in, you have to read off the type, min, max, step, and value attributes of the <super-slider> element, then create an <input> element and add the attributes and their values you just read off <super-slider>, create a <label> and insert the <super-slider>’s text content into the label’s text content, and why? Why did I do this to myse — uh, I mean, why do this to yourself?
This is the pattern I got from <fit-vids>, and the moment that really broke down the barrier I’d had to understanding what makes web components so valuable. By taking this approach, you get everything HTML gives you with the <label> and <input> elements for free, and you can add things on top of it. It’s pure progressive enhancement.
To figure out how all this goes together, I found MDN’s page “Using custom elements” really quite valuable. That’s where I internalized the reality that instead of having to scrape the DOM for custom elements and then run through a loop, I could extend HTML itself:
class superSlider extends HTMLElement {
connectedCallback() {
//
// the magic happens here!
//
}
}
customElements.define("super-slider",superSlider);
What that last line does is tell the browser, “any <super-slider> element is of the superSlider JavaScript class”. Which means, any time the browser sees <super-slider>, it does the stuff that’s defined by class superSlider in the script. Which is the thing in the previous code block! So let’s talk about how it works, with concrete examples.
It’s the class structure that holds the real power. Inside there, connectedCallback() is invoked whenever a <super-slider> is connected; that is, whenever one is encountered in the page by the browser as it parses the markup, or when one is added to the page later on. It’s an auto-startup callback. (What’s a callback? I’ve never truly understood that, but it turns out I don’t have to!) So in there, I write something like:
connectedCallback() {
let targetEl = document.querySelector(this.getAttribute('target'));
let unit = this.getAttribute('unit');
let slider = this.querySelector('input[type="range"]');
}
So far, all I’ve done here is:
Used the value of the target attribute on <super-slider> to find the element that the range slider should affect using a CSS-esque query.
The unit attribute’s value to know what CSS unit I’ll be using later in the code.
Grabbed the range input itself by running a querySelector() within the <super-slider> element.
With all those things defined, I can add an event listener to the range input:
slider.addEventListener("input",(e) => {
let value = slider.value + unit;
targetEl.style.setProperty('font-size',value);
});
…and really, that’s it. Put all together:
class superSlider extends HTMLElement {
connectedCallback() {
let targetEl = document.querySelector(this.getAttribute('target'));
let unit = this.getAttribute('unit');
let slider = this.querySelector('input[type="range"]');
slider.addEventListener("input",(e) => {
targetEl.style.setProperty('font-size',slider.value + unit);
});
}
}
customElements.define("super-slider",superSlider);
<span>See the Pen <a href="https://codepen.io/meyerweb/pen/oNmXJRX">
WebCOLD 01</a> by Eric A. Meyer (<a href="https://codepen.io/meyerweb">@meyerweb</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
As I said earlier, you can get to essentially the same result by running document.querySelectorAll('super-slider') and then looping through the collection to find all the bits and bobs and add the event listeners and so on. In a sense, that’s what I’ve done above, except I didn’t have to do the scraping and looping and waiting until the document has loaded — using web components abstracts all of that away. I’m also registering all the components with the browser via customElements.define(), so there’s that too. Overall, somehow, it just feels cleaner.
One thing that sets customElements.define() apart from the collect-and-loop-after-page-load approach is that custom elements fire all that connection callback code on themselves whenever they’re added to the document, all nice and encapsulated. Imagine for a moment an application where custom elements are added well after page load, perhaps as the result of user input. No problem! There isn’t the need to repeat the collect-and-loop code, which would likely have to have special handling to figure out which are the new elements and which already existed. It’s incredibly handy and much easier to work with.
But that’s not all! Suppose we want to add a “reset” button — a control that lets you set the slider back to its starting value. Adding some code to the connectedCallback() can make that happen. There’s probably a bunch of different ways to do this, so what follows likely isn’t the most clever or re-usable way. It is, instead, the way that made sense to me at the time.
With that code added into the connection callback, a button gets added right after the slider, and it shows a little circle-arrow to convey the concept of resetting. You could just as easily make its text “Reset”. When said button is clicked or keyboard-activated ("click" handles both, it seems), the slider is reset to the stored initial value, and then an input event is fired at the slider so the target element’s style will also be updated. This is probably an ugly, ugly way to do this! I did it anyway.
<span>See the Pen <a href="https://codepen.io/meyerweb/pen/jOdPdyQ">
WebCOLD 02</a> by Eric A. Meyer (<a href="https://codepen.io/meyerweb">@meyerweb</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
Okay, so now that I can reset the value, maybe I’d also like to see what the value is, at any given moment in time? Say, by inserting a classed <span> right after the label and making its text content show the current combination of value and unit?
let label = this.querySelector('label');
let readout = document.createElement('span');
readout.classList.add('readout');
readout.textContent = slider.value + unit;
label.after(readout);
Plus, I’ll need to add the same text content update thing to the slider’s handling of input events:
I imagine I could have made this readout-updating thing a little more generic (less DRY, if you like) by creating some kind of getter/setter things on the JS class, which is totally possible to do, but that felt like a little much for this particular situation. Or I could have broken the readout update into its own function, either within the class or external to it, and passed in the readout and slider and reset value and unit to cause the update. That seems awfully clumsy, though. Maybe figuring out how to make the span a thing that observes slider changes and updates automatically? I dunno, just writing the same thing in two places seemed a lot easier, so that’s how I did it.
So, at this point, here’s the entirety of the script, with a CodePen example of the same thing immediately after.
class superSlider extends HTMLElement {
connectedCallback() {
let targetEl = document.querySelector(this.getAttribute("target"));
let unit = this.getAttribute("unit");
let slider = this.querySelector('input[type="range"]');
slider.addEventListener("input", (e) => {
targetEl.style.setProperty("font-size", slider.value + unit);
readout.textContent = slider.value + unit;
});
let reset = slider.getAttribute("value");
let resetter = document.createElement("button");
resetter.textContent = "↺";
resetter.setAttribute("title", reset + unit);
resetter.addEventListener("click", (e) => {
slider.value = reset;
slider.dispatchEvent(
new MouseEvent("input", { view: window, bubbles: false })
);
});
slider.after(resetter);
let label = this.querySelector("label");
let readout = document.createElement("span");
readout.classList.add("readout");
readout.textContent = slider.value + unit;
label.after(readout);
}
}
customElements.define("super-slider", superSlider);
<span>See the Pen <a href="https://codepen.io/meyerweb/pen/NWoGbWX">
WebCOLD 03</a> by Eric A. Meyer (<a href="https://codepen.io/meyerweb">@meyerweb</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
Anything you can imagine JS would let you do to the HTML and CSS, you can do in here. Add a class to the slider when it has a value other than its default value so you can style the reset button to fade in or be given a red outline, for example.
Or maybe do what I did, and add some structural-fix-up code. For example, suppose I were to write:
In that bit of markup, I left off the id on the <input> and the for on the <label>, which means they have no structural association with each other. (You should never do this, but sometimes it happens.) To handle this sort of failing, I threw some code into the connection callback to detect and fix those kinds of authoring errors, because why not? It goes a little something like this:
if (!label.getAttribute('for') && slider.getAttribute('id')) {
label.setAttribute('for',slider.getAttribute('id'));
}
if (label.getAttribute('for') && !slider.getAttribute('id')) {
slider.setAttribute('id',label.getAttribute('for'));
}
if (!label.getAttribute('for') && !slider.getAttribute('id')) {
let connector = label.textContent.replace(' ','_');
label.setAttribute('for',connector);
slider.setAttribute('id',connector);
}
Once more, this is probably the ugliest way to do this in JS, but also again, it works. Now I’m making sure labels and inputs have association even when the author forgot to explicitly define it, which I count as a win. If I were feeling particularly spicy, I’d have the code pop an alert chastising me for screwing up, so that I’d fix it instead of being a lazy author.
It also occurs to me, as I review this for publication, that I didn’t try to do anything in situations where both the for and id attributes are present, but their values don’t match. That feels like something I should auto-fix, since I can’t imagine a scenario where they would need to intentionally be different. It’s possible my imagination is lacking, of course.
So now, here’s all just-over-40 lines of the script that makes all this work, followed by a CodePen demonstrating it.
class superSlider extends HTMLElement {
connectedCallback() {
let targetEl = document.querySelector(this.getAttribute("target"));
let unit = this.getAttribute("unit");
let slider = this.querySelector('input[type="range"]');
slider.addEventListener("input", (e) => {
targetEl.style.setProperty("font-size", slider.value + unit);
readout.textContent = slider.value + unit;
});
let reset = slider.getAttribute("value");
let resetter = document.createElement("button");
resetter.textContent = "↺";
resetter.setAttribute("title", reset + unit);
resetter.addEventListener("click", (e) => {
slider.value = reset;
slider.dispatchEvent(
new MouseEvent("input", { view: window, bubbles: false })
);
});
slider.after(resetter);
let label = this.querySelector("label");
let readout = document.createElement("span");
readout.classList.add("readout");
readout.textContent = slider.value + unit;
label.after(readout);
if (!label.getAttribute("for") && slider.getAttribute("id")) {
label.setAttribute("for", slider.getAttribute("id"));
}
if (label.getAttribute("for") && !slider.getAttribute("id")) {
slider.setAttribute("id", label.getAttribute("for"));
}
if (!label.getAttribute("for") && !slider.getAttribute("id")) {
let connector = label.textContent.replace(" ", "_");
label.setAttribute("for", connector);
slider.setAttribute("id", connector);
}
}
}
customElements.define("super-slider", superSlider);
<span>See the Pen <a href="https://codepen.io/meyerweb/pen/PoVPbzK">
WebCOLD 04</a> by Eric A. Meyer (<a href="https://codepen.io/meyerweb">@meyerweb</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
There are doubtless cleaner/more elegant/more clever ways to do pretty much everything I did above, considering I’m not much better than an experienced amateur when it comes to JavaScript. Don’t focus so much on the specifics of what I wrote, and more on the overall concepts at play.
I will say that I ended up using this custom element to affect more than just font sizes. In some places I wanted to alter margins; in others, the hue angle of colors. There are a couple of ways to do this. The first is what I did, which is to use a bunch of CSS variables and change their values. So the markup and relevant bits of the JS looked more like this:
I’ll leave the associated JS as an exercise for the reader. I can think of reasons to do either of those approaches.
But wait! There’s more! Not more in-depth JS coding (even though we could absolutely keep going, and in the tool I built, I absolutely did), but there are some things to talk about before wrapping up.
First, if you need to invoke the class’s constructor for whatever reason — I’m sure there are reasons, whatever they may be — you have to do it with a super() up top. Why? I don’t know. Why would you need to? I don’t know. If I read the intro to the super page correctly, I think it has something to do with class prototypes, but the rest went so far over my head the FAA issued a NOTAM. Apparently I didn’t do anything that depends on the constructor in this article, so I didn’t bother including it.
Second, basically all the JS I wrote in this article went into the connectedCallback() structure. This is only one of four built-in callbacks! The others are:
disconnectedCallback(), which is fired whenever a custom element of this type is removed from the page. This seems useful if you have things that can be added or subtracted dynamically, and you want to update other parts of the DOM when they’re subtracted.
adoptedCallback(), which is (to quote MDN) “called each time the element is moved to a new document.” I have
no idea what that means. I understand all the words; it’s just that particular combination of them that confuses me.
attributeChangedCallback(), which is fired when attributes of the custom element change. I thought about trying to use this for my super-sliders, but in the end, nothing I was doing made sense (to me) to bubble up to the custom element just to monitor and act upon. A use case that does suggest itself: if I allowed users to change the sizing unit, say from
em to
vh, I’d want to change other things, like the
min,
max,
step, and default
value attributes of the sliders. So, since I’d have to change the value of the
unit attribute anyway, it might make sense to use
attributeChangedCallback() to watch for that sort of thing and then take action. Maybe!
Third, I didn’t really talk about styling any of this. Well, because all of this stuff is in the Light DOM, I don’t have to worry about Shadow Walls or whatever, I can style everything the normal way. Here’s a part of the CSS I use in the CodePens, just to make things look a little nicer:
Hopefully that all makes sense, but if not, let me know in the comments and I’ll clarify.
A thing I didn’t do was use the :defined pseudo-class to style custom elements that are defined, or rather, to style those that are not defined. Remember the last line of the script, where customElements.define() is called to define the custom elements? Because they are defined that way, I could add some CSS like this:
super-slider:not(:defined) {
display: none;
}
In other words, if a <super-slider> for some reason isn’t defined, make it and everything inside it just… go away. Once it becomes defined, the selector will no longer match, and the display: none will be peeled away. You could use visibility or opacity instead of display; really, it’s up to you. Heck, you could tile red warning icons in the whole background of the custom element if it hasn’t been defined yet, just to drive the point home.
The beauty of all this is, you don’t have to mess with Shadow DOM selectors like ::part() or ::slotted(). You can just style elements the way you always style them, whether they’re built into HTML or special hyphenated elements you made up for your situation and then, like the Boiling Isles’ most powerful witch, called into being.
That said, there’s a “fourth” here, which is that Shadow DOM does offer one very powerful capability that fully Light DOM custom elements lack: the ability to create a structural template with <slot> elements, and then drop your Light-DOM elements into those slots. This slotting ability does make Shadowy web components a lot more robust and easier to share around, because as long as the slot names stay the same, the template can be changed without breaking anything. This is a level of robustness that the approach I explored above lacks, and it’s built in. It’s the one thing I actually do like about Shadow DOM.
It’s true that in a case like I’ve written about here, that’s not a huge issue: I was quickly building a web component for a single tool that I could re-use within the context of that tool. It works fine in that context. It isn’t portable, in the sense of being a thing I could turn into an npm package for others to use, or probably even share around my organization for other teams to use. But then, I only put 40-50 lines worth of coding into it, and was able to rapidly iterate to create something that met my needs perfectly. I’m a lot more inclined to take this approach in the future, when the need arises, which will be a very powerful addition to my web development toolbox.
I’d love to see the templating/slotting capabilities of Shadow DOM brought into the fully Light-DOM component world. Maybe that’s what Declarative Shadow DOM is? Or maybe not! My eyes still go cross-glazed whenever I try to read articles about Shadow DOM, almost like a trickster demon lurking in the shadows casts a Spell of Confusion at me.
So there you have it: a few thousand words on my journey through coming to understand and work with these fully-Light-DOM web components, otherwise known as custom elements. Now all they need is a catchy name, so we can draw more people to the Light Side of the Web. If you have any ideas, please drop ’em in the comments!
I’ve posted a followup to this post which you should read before you read this post, because you might decide there’s no need to read this one. If not, please note that what’s documented below was a hack to overcome a bug that was quickly fixed, in a part of CSS that wasn’t enabled in stable Firefox at the time I wrote the post. Thus, what follows isn’t really useful, and leaves more than one wrong impression. I apologize for this. For a more detailed breakdown of my errors, please see the followup post.
I’ve been doing some development recently on a tool that lets me quickly produce social-media banners for my work at Igalia. It started out using a vanilla JS script to snarfle up collections of HTML elements like all the range inputs, stick listeners and stuff on them, and then alter CSS variables when the inputs change. Then I had a conceptual breakthrough and refactored the entire thing to use fully light-DOM web components (FLDWCs), which let me rapidly and radically increase the tool’s capabilities, and I kind of love the FLDWCs even as I struggle to figure out the best practices.
With luck, I’ll write about all that soon, but for today, I wanted to share a little hack I developed to make Firefox a tiny bit more capable.
One of the things I do in the tool’s CSS is check to see if an element (represented here by a <div> for simplicity’s sake) has an image whose src attribute is a base64 string instead of a URI, and when it is, add some generated content. (It makes sense in context. Or at least it makes sense to me.) The CSS rule looks very much like this:
div:has(img[src*=";data64,"])::before {
[…generated content styles go here…]
}
This works fine in WebKit and Chromium. Firefox, at least as of the day I’m writing this, often fails to notice the change, which means the selector doesn’t match, even in the Nightly builds, and so the generated content isn’t generated. It has problems correlating DOM updates and :has(), is what it comes down to.
There is a way to prod it into awareness, though! What I found during my development was that if I clicked or tabbed into a contenteditable element, the :has() would suddenly match and the generated content would appear. The editable element didn’t even have to be a child of the div bearing the :has(), which seemed weird to me for no distinct reason, but it made me think that maybe any content editing would work.
I tried adding contenteditable to a nearby element and then immediately removing it via JS, and that didn’t work. But then I added a tiny delay to removing the contenteditable, and that worked! I feel like I might have seen a similar tactic proposed by someone on social media or a blog or something, but if so, I can’t find it now, so my apologies if I ganked your idea without attribution.
My one concern was that if I wasn’t careful, I might accidentally pick an element that was supposed to be editable, and then remove the editing state it’s supposed to have. Instead of doing detection of the attribute during selection, I asked myself, “Self, what’s an element that is assured to be present but almost certainly not ever set to be editable?”
Well, there will always be a root element. Usually that will be <html> but you never know, maybe it will be something else, what with web components and all that. Or you could be styling your RSS feed, which is in fact a thing one can do. At any rate, where I landed was to add the following right after the part of my script where I set an image’s src to use a base64 URI:
let ffHack = document.querySelector(':root');
ffHack.setAttribute('contenteditable','true');
setTimeout(function(){
ffHack.removeAttribute('contenteditable');
},7);
Literally all this does is grab the page’s root element, set it to be contenteditable, and then seven milliseconds later, remove the contenteditable. That’s about a millisecond less than the lifetime of a rendering frame at 120fps, so ideally, the browser won’t draw a frame where the root element is actually editable… or, if there is such a frame, it will be replaced by the next frame so quickly that the odds of accidentally editing the root are very, very, very small.
At the moment, I’m not doing any browser sniffing to figure out if the hack needs to be applied, so every browser gets to do this shuffle on Firefox’s behalf. Lazy, I suppose, but I’m going to wave my hands and intone “browsers are very fast now” while studiously ignoring all the inner voices complaining about inefficiency and inelegance. I feel like using this hack means it’s too late for all those concerns anyway.
I don’t know how many people out there will need to prod Firefox like this, but for however many there are, I hope this helps. And if you have an even better approach, please let us know in the comments!
Yesterday, I was looking at an existing page, wondering if it would be improved by rearranging some of the elements. I was about to fire up the git engine (spawn a branch, check it out, do edits, preview them, commit changes, etc., etc.) when I got a weird thought: could I just drag elements around in the Web Inspector in my browser of choice, Firefox Nightly, so as to quickly try out various changes without having to open an editor? Turns out the answer is yes, as demonstrated in this video!
Youtube: “Dragging elements in Firefox Nightly’s Web Inspector”
Since I recorded the video, I’ve learned that this same capability exists in public-release Firefox, and has been in Chrome for a while. It’s probably been in Firefox for a while, too. What I was surprised to find was how many other people were similarly surprised that this is possible, which is why I made the video. It’s probably easier to understand to video if it’s full screen, or at least expanded, but I think the basic idea gets across even in small-screen format. Share and enjoy!
function fixCCP() {
var elems = document.getElementsByTagName('*');
var attrs = ['onpaste','oncopy','oncut'];
for (i = 0; i < elems.length; i++) {
for (j = 0; j < attrs.length; j++) {
if (elems[i].getAttribute(attrs[j])) {
elems[i].setAttribute(attrs[j],elems[i]
.getAttribute(attrs[j])
.replace("return false","return true"));
}
}
}
}
Here it is as a bookmarklet, if you still roll that way (as I do):
fixCCP. Thanks to the Bookmarklet Maker at bookmarklets.org for helping me out with that!
If there are obvious improvements to be made to its functionality, let me know and I’ll throw it up on Github.
This morning I caught a pointer to TypeButter, which is a jQuery library that does “optical kerning” in an attempt to improve the appearance of type. I’m not going to get into its design utility because I’m not qualified; I only notice kerning either when it’s set insanely wide or when it crosses over into keming. I suppose I’ve been looking at web type for so many years, it looks normal to me now. (Well, almost normal, but I’m not going to get into my personal typographic idiosyncrasies now.)
My reason to bring this up is that I’m very interested by how TypeButter accomplishes its kerning: it inserts kern elements with inline style attributes that bear letter-spacing values. Not span elements, kern elements. No, you didn’t miss an HTML5 news bite; there is no kern element, nor am I aware of a plan for one. TypeButter basically invents a specific-purpose element.
I believe I understand the reasoning. Had they used span, they would’ve likely tripped over existing author styles that apply to span. Browsers these days don’t really have a problem accepting and styling arbitrary elements, and any that do would simply render type their usual way. Because the markup is script-generated, markup validation services don’t throw conniption fits. There might well be browser performance problems, particularly if you optically kern all the things, but used in moderation (say, on headings) I wouldn’t expect too much of a hit.
The one potential drawback I can see, as articulated by Jake Archibald, is the possibility of a future kern element that might have different effects, or at least be styled by future author CSS and thus get picked up by TypeButter’s kerns. The currently accepted way to avoid that sort of problem is to prefix with x-, as in x-kern. Personally, I find it deeply unlikely that there will ever be an official kern element; it’s too presentationally focused. But, of course, one never knows.
If TypeButter shifted to generating x-kern before reaching v1.0 final, I doubt it would degrade the TypeButter experience at all, and it would indeed be more future-proof. It’s likely worth doing, if only to set a good example for libraries to follow, unless of course there’s downside I haven’t thought of yet. It’s definitely worth discussing, because as more browser enhancements are written, this sort of issue will come up more and more. Settling on some community best practices could save us some trouble down the road.
Update 23 Mar 12: it turns out custom elements are not as simple as we might prefer; see the comment below for details. That throws a fairly large wrench into the gears, and requires further contemplation.
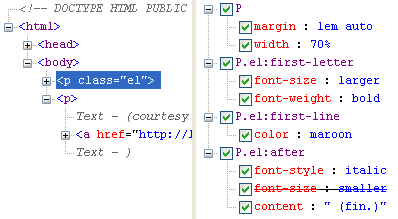
In the course of a recent debugging session, I discovered a limitation of web inspectors (Firebug, Dragonfly, Safari’s Web Inspector, et al.) that I hadn’t quite grasped before: they don’t show pseudo-elements and they’re not so great with pseudo-classes. There’s one semi-exception to this rule, which is Internet Explorer 8’s built-in Developer Tool. It shows pseudo-elements just fine.
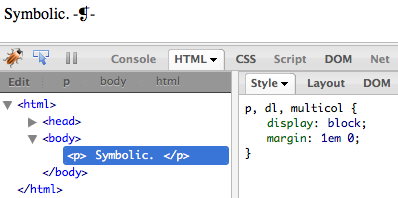
Drop that style into any document that has paragraphs. Load it up in your favorite development browser. Now inspect a paragraph. You will not see the generated content in the DOM view, and you won’t see the pseudo-element rule in the Styles tab (except in IE, where you get the latter, though not the former).
The problem isn’t that I used an escaped Unicode reference; take that out and you’ll still see the same results, as on the test page I threw together. It isn’t the double-colon syntax, either, which all modern browsers handle just fine; and anyway, I can take it back to a single colon and still see the same results. ::first-letter, ::first-line, ::before, and ::after are all basically invisible in most inspectors.
This can be a problem when developing, especially in cases such as having a forgotten, runaway generated-content clearfix making hash of the layout. No matter how many times you inspect the elements that are behaving strangely, you aren’t going to see anything in the inspector that tells you why the weirdness is happening.
The same is largely true for dynamic pseudo-classes. If you style all five link states, only two will show up in most inspectors—either :link or :visited, depending on whether you’ve visited the link’s target; and :focus. (You can sometimes also get :hover in Dragonfly, though I’ve not been able to do so reliably. IE8’s Developer Tool always shows a:link even when the link is visited, and doesn’t appear to show any other link states. …yes, this is getting complicated.)
The more static pseudo-classes, like :first-child, do show up pretty well across the board (except in IE, which doesn’t support all the advanced static pseudo-classes; e.g., :last-child).
I can appreciate that inspectors face an interesting challenge here. Pseudo-elements are just that, and aren’t part of the actual structure. And yet Internet Explorer’s Developer Tool manages to find those rules and display them without any fuss, even if it doesn’t show generated content in its DOM view. Some inspectors do better than others with dynamic pseudo-classes, but the fact remains that you basically can’t see some of them even though they will potentially apply to the inspected link at some point.
I’d be very interested to know what inspector teams encountered in trying to solve this problem, or if they’ve never tried. I’d be especially interested to know why IE shows pseudo-elements when the others don’t—is it made simple by their rendering engine’s internals, or did someone on the Developer Tool team go to the extra effort of special-casing those rules?
For me, however, the overriding question is this: what will it take for the various inspectors to behave more like IE’s does, and show pseudo-element and pseudo-class rules that are associated with the element currently being inspected? And as a bonus, to get them to show in the DOM view where the pseudo-elements actually live, so to speak?
(Addendum: when I talk about IE and the Developer Tool in this post, I mean the tool built into IE8. I did not test the Developer Toolbar that was available for IE6 and IE7. Thanks to Jeff L for pointing out the need to be clear about that.)
{kind=link}