Better PDF File Size Reduction in OS X
Published 16 years, 1 month pastOne of the things you discover as a speaker and, especially, a conference organizer is this: Keynote generates really frickin’ enormous PDFs. Seriously. Much like Miles O’Keefe, they’re huge. We had one speaker last year whose lovingly crafted and beautifully designed 151-slide deck resulted in a 175MB PDF.
Now, hard drives and bandwidth may be cheap, but when you have four hundred plus attendees all trying to download the same 175MB PDF at the same time, the venue’s conference manager will drop by to find out what the bleeding eyestalks your attendees are doing and why it’s taking down the entire outbound pipe. Not to mention the network will grind to a nearly complete halt. Whatever you personally may think of net access at conferences, at this point, not providing net access is roughly akin to not providing functioning bathrooms.
So what’s the answer? ShrinkIt is fine if the slides use lots of vectors and you’re running Snow Leopard. If the slides use lots of bitmapped images, or you’re not on Snow Leopard, ShrinkIt can’t help you.
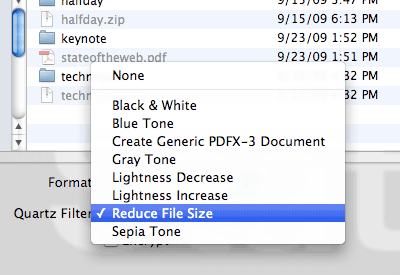
If the slides are image-heavy, then you can always load the PDF into Preview and then do a “Save As…” where you select the “Reduce File Size” Quartz filter. That will indeed drastically shrink the file size — that 175MB PDF goes down to 13MB — but it can also make the slides look thoroughly awful. That’s because the filter achieves its file size reduction by scaling all the images down by at least 50% and to no more than 512 pixels on a side, plus it uses aggressive JPEG compression. So not only are the images infested with compression artifacts, they also tend to get that lovely up-scaling blur. Bleah.
I Googled around a bit and found “Quality reduced file size in Mac OS X Preview” from early 2006. There I discovered that anyone can create their own Quartz filters, which was the key I needed. Thus armed with knowledge, I set about creating a filter that struck, in my estimation, a reasonable balance between image quality and file size reduction. And I think I’ve found it. That 175MB PDF gets taken down to 34MB with what I created.
If you’d like to experience this size reduction for yourself (and how’s that for an inversion of common spam tropes?) it’s pretty simple:
- Download and unzip Reduce File Size (75%). Note that the “75%” relates to settings in the filter, not the amount of reduction you’ll get by using it.
- Drop the unzipped .qfilter file into ~/Library/Filters in Leopard/Snow Leopard or /Library/PDF Services in Lion. (Apparently no
~in Lion.)
Done. The next time you need to reduce the size of a PDF, load it up in Preview, choose “Save As…”, and save it using the Quartz filter you just installed.
If you’re the hands-on type who’d rather set things up yourself, or you’re a paranoid type who doesn’t trust downloading zipped files from sites you don’t control (and I actually don’t blame you if you are), then you can manually create your own filter like so:
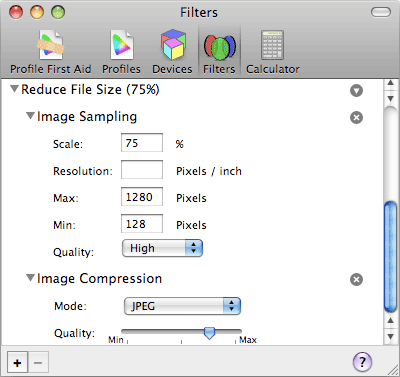
- Go to /Applications/Utilities and launch ColorSync Utility.
- Select the “Filters” icon in the application’s toolbar.
- Find the “Reduce File Size” filter and click on the little downward-arrow-in-gray-circle icon to the right.
- Choose “Duplicate Filter” in the menu.
- Use the twisty arrow to open the duplicated filter, then open each of “Image Sampling” and “Image Compression”.
- Under “Image Sampling”, set “Scale” to 75% and “Max” to 1280.
- Under “Image Compression”, move the arrow so it’s halfway between the rightmost marks. You’ll have to eyeball it (unless you bust out xScope or a similar tool) but you should be able to get it fairly close to the halfway point.
- Rename the filter to whatever will help you remember its purpose.
As you can see from the values, the “75%” part of the filter’s name comes from the fact that two of the filter’s values are 75%. In the original Reduce File Size filter, both are at 50%. The maximum size of images in my version is also quite a bit bigger than the original’s — 1280 versus 512 — which means that the file size reductions won’t be the same as the original.
Of course, you now have the knowledge needed to fiddle with the filter to create your own optimal balance of quality and compression, whether you downloaded and installed the zip or set it up manually — either way, ColorSync Utility has what you need. If anyone comes up with an even better combination of values, I’d love to hear about it in the comments. In the meantime, share and enjoy!
Translations
- Belorussian courtesy Patricia Clausnitzer
- German courtesy Andreas Beraz
Update 2 Aug 11: apparently there have been changes in Lion — here’s an Apple forum discussion of the problem. There are two workarounds described in the thread: either to open and save files with ColorSync Utility itself, or to copy the filter to another folder in your Library (or install it there in the first place, above).
Update 27 Mar 12: edited the Lion install directory to remove an errant ~ . Thanks to Brian Christiansen for catching the error!